一、前言
软件开发活动中,涉及多项目、多角色、多人员,跨组织、跨时间、跨地域。效率、质量、成本这三个问题, 夹杂在其中,反复权衡,但其实大家最终的目的只有一句话:保质保量的快速交付。
提升研发效能,主要是关注业务交付链条中研发交付环节的品控和效率,最核心的是缩短优质代码到客户交付间的距离, 建立一个高速信息通道,量化可视化交付能力,最终形成反馈循环持续改进。
在推进EP相关实践的过程中,需要充分利用现有的工具,搭建质量、效率的度量指标体系。其中在获取到相应数据前, 需要规范研发流程。利用TAPD管理研发全生命周期,缩短不必要的时间浪费,获取度量数据,进行可视化分析。 本文主要介绍了几个比较Highlight的TAPD使用方式,初有成效。
二、背景
按照最开始设立的EP试点方案,等到了12月份,就开始准备总结,沉淀,发文了。只是近期部门内部知识分享小组的KPI发起, 加上不断有人询问,希望复制到其他项目组,而且TAPD的同事诚心邀请撰文。在这个档口,把原计划准备的内容,连夜赶文部分出来, 参加【TAPD实战故事】活动,算是提前总结顺便收获小礼品吧。
三、迭代管理
在整个的迭代管理中,不同成熟度的项目,会在各个阶段遇到不同的问题,下面按照任务类型,着重挑出几个共性问题,进行展开。
1. 迭代
1.1 问题
在使用TAPD时,每个角色关注的维度不一样,关注点也不一样,甚至在关注同一个事情的阶段也不一样。这些散落的关注点, 如果有一条线可以串联起来,所有的角色就可以on the same page,时刻知道项目roadmap的主线了。
1.2 解决思路
考虑到产品、设计、开发、测试等角色的分工,安排给每个角色一个独立的任务,比如产品主要关注需求,开发关注任务和缺陷, 测试关注提测任务和缺陷。
将所有的任务,放在迭代里面统筹管理,关系如下: 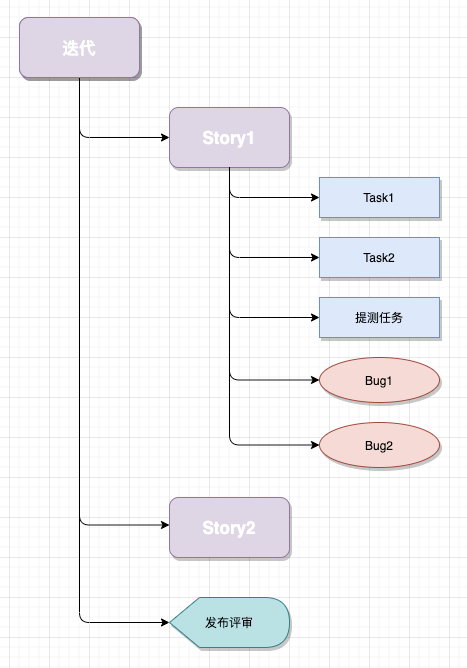
- 每个迭代,只关注本迭代的需求、任务和Bug。
- 如果Bug此期优先级不高,挂起之后挪到后面的迭代。
1.3 效果
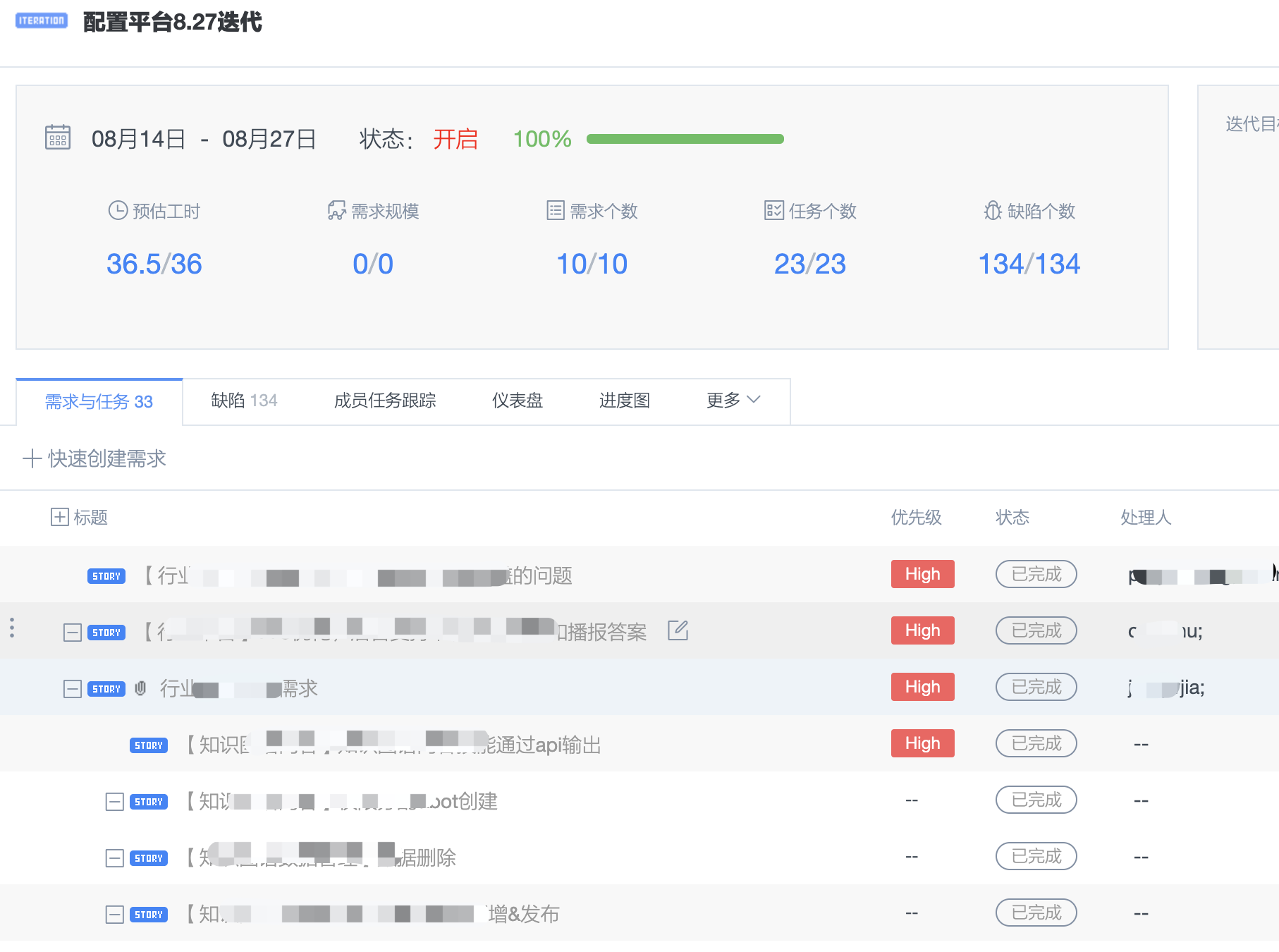
-
需求、任务、缺陷,全部放在了迭代里
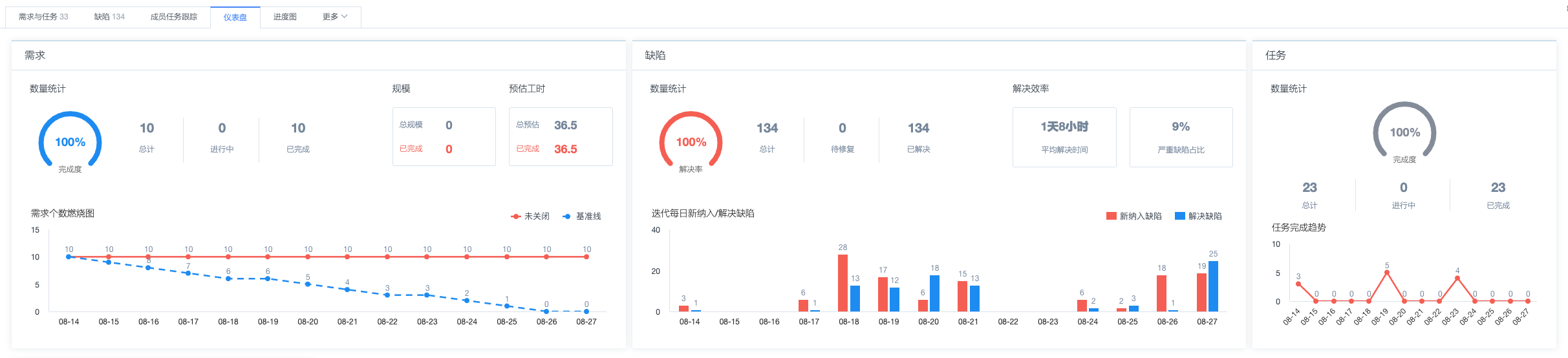
-
仪表盘查看需求、缺陷、任务完成情况
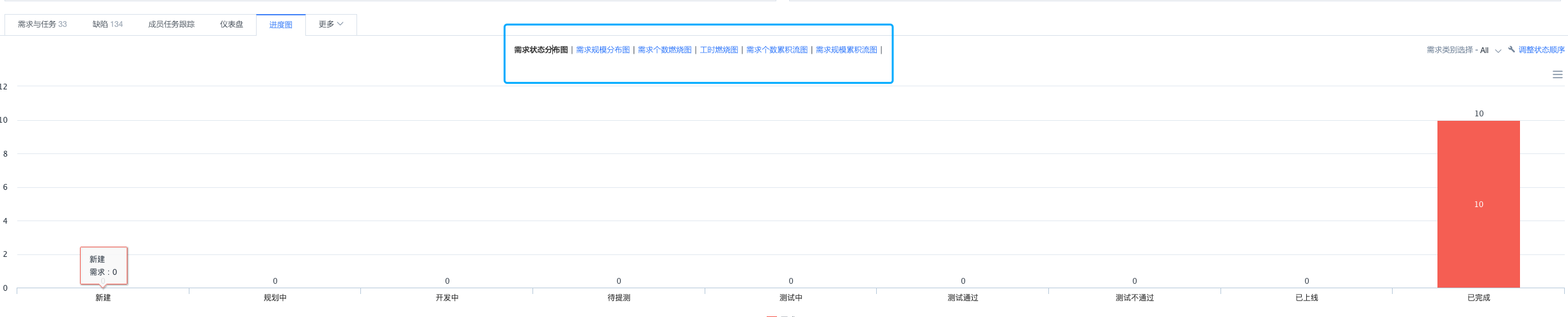
-
进度图,实时查看需求状态分布图、需求规模分布图等
2. 需求
2.1 问题
需求一般会经历产品规划→UI/UX设计→开发→测试→验收→上线,那么如何知道进度,并及时获知是否有风险呢? 通过某种方式(纸笔或者跟踪系统)来记录是可以达到的。
那么问题来了,是来谁记录呢?如果工作全部交给一个人,需要此人对每个领域的专业术语都有认知, 并时刻去跟进。如果需求多了,那么这个人的就只能每天跟进进度了。如果项目团队里,没有一个这样的人或者角色来处理, 那该如何是好?需求先流动起来,才能看到价值,才能进一步推进需求的其他改善,比如拆解需求等。
2.2 解决思路
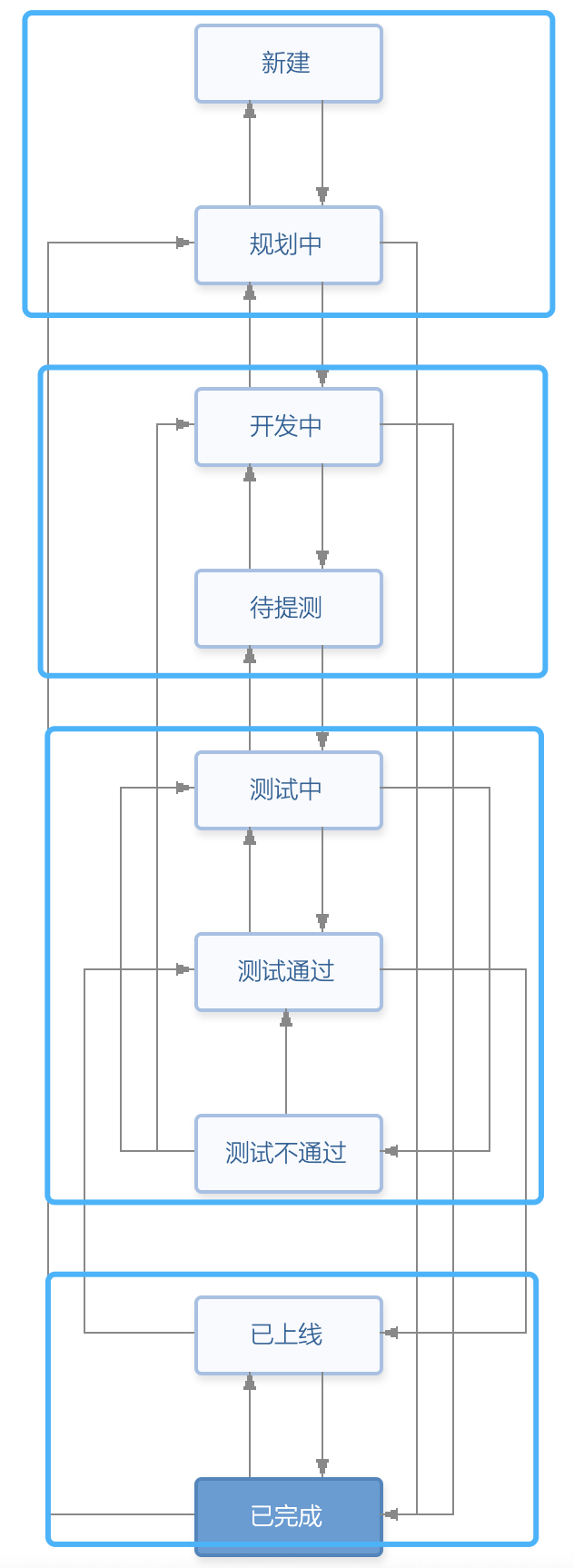
在TAPD里,设置需求的工作流之后,按照角色划分职责,各司其职,每个阶段处理人一般都只分配一个人, 形成Owner意识。比如:
- 产品负责:
- 「新建」到「规划」
- 「已上线」到「已完成」
- 开发负责:
- 「规划」到「开发中」
- 「开发」到「待提测」
- 「测试通过」到「已上线」
- 测试负责:
- 「待提测」到「测试中」
- 「测试中」到「测试不通过」「测试通过」
2.3 推进
从质量侧进行推进:
- 提测时候,严格要求需求必须是「待提测状态」,才开始测试。
- 需求为「测试不通过」,发送测试不通过报告,无法上线。
进一步推进:
- 需求长期处于开发中,拉长战线,那么是否可以拆解,并对拆解后的小需求提测上线。 需求拆解可参考:
- 内网[【DevOps】从提高研发效率的角度聊聊产品需求拆解]
- 本站庖丁解牛-需求拆解的十种策略
- 需求预计开发结束时间快到了,是否可以提前计划测试人力
3. 任务
3.1 问题
一个需求,可能涉及到很多人,包括不同团队的,包括前端、后端、移动端等等。如果全部挂在这个需求上, 没有Owner意识感。如果创建很多需求,每个人分配有一个,倒显得刻意为之,增加很多状态扭转的工作量。
3.2 解决思路
用轻量级的任务,给研发同学或者其他参与同学提供一个方案,显得便捷很多。任务只涉及到「未开始」 「进行中」「已完成」三个状态。
- 当涉及到多个端的时候,每个端都可以有一个任务,甚至可以多加一个联调的任务。
- 每个任务都可以进行预估时间,时间会自动叠加到需求上去。
3.3 效果
将需求拆解为研发任务,可以提前估算需求的大致时间,也给开发同学列了一个ToDo List逐步开发。 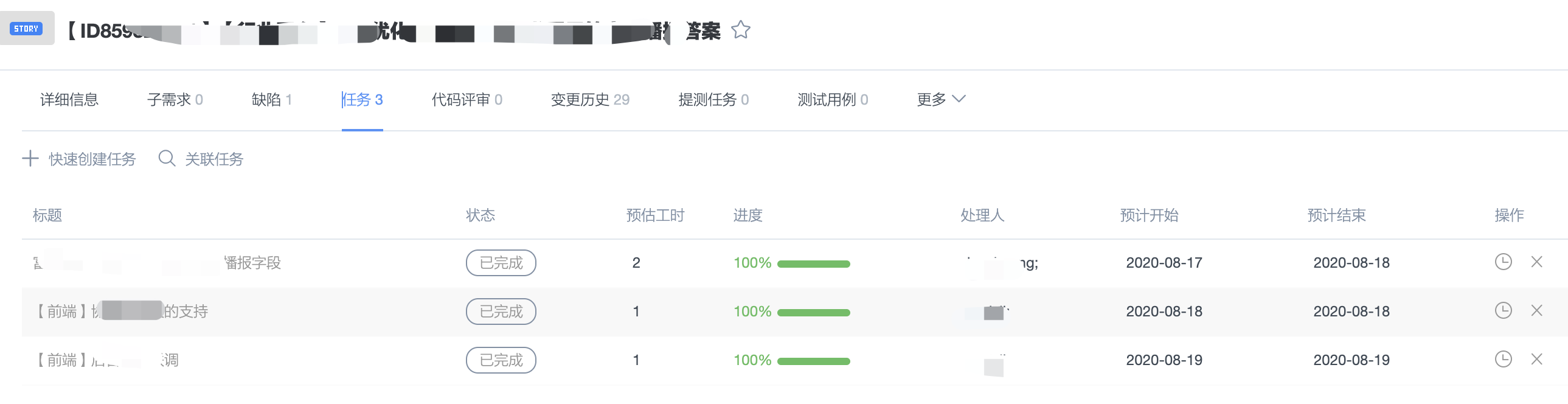
4. 缺陷
4.1 问题
每次测试出来好多Bug,如何高效跟进?
4.2 解决思路
- 创建时候,增加Bug的相关信息,比如优先级、严重程度、版本、模块等,便于快速筛选。
- 解决时候,填写产生原因、解决办法,便于迭代末进行缺陷的ODC分析。
- 关联时候,关联到迭代、需求上。
- 抛出问题时,一键拉群,小群解决。
- 添加TAPD机器人,定期辅助提醒。
4.3 推进
- 及时组织Bug Review,高级筛选剩下关注的Bug,快速决定Bug的处理状态
- 及时添加评论,根据评论查看重要信息(不用翻聊天记录)
- 处理人原则,不是自己名下的Bug,及时分配出去(后面结合报表-统计来看)
5. 提测任务
5.1 问题
测试同学在测试的时候,有可能是多个需求进行一起提测,有可能是多个Bug进行提测,或者是集成测试提测需要 涵盖的Scope需要一个地方单独指明。那么如何标记每一次的提测呢?每一次提测的测试要点是什么呢?放在哪里管理呢?
5.2 解决思路
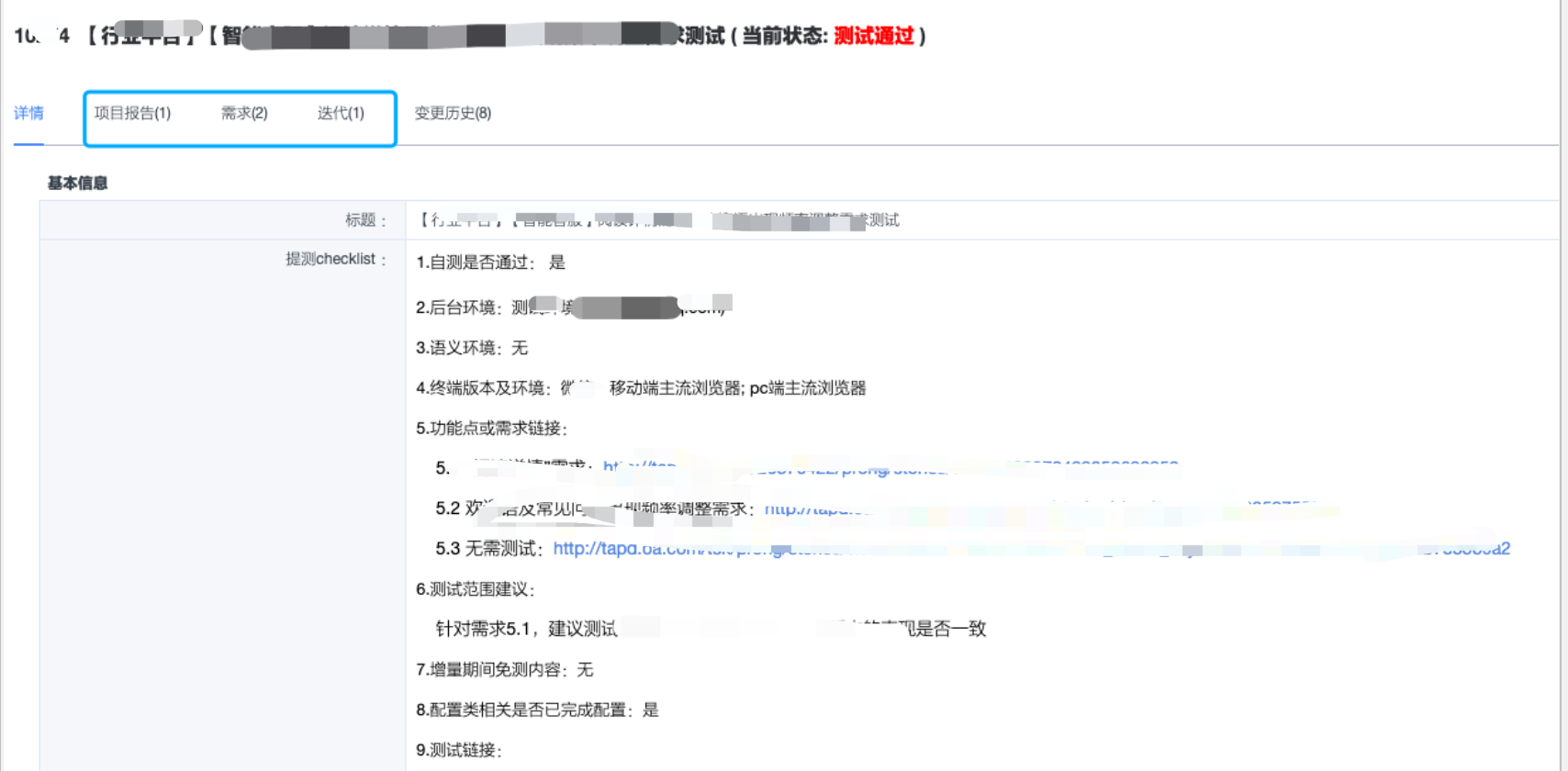
- 如果说任务是开发专属,那么提测任务就是测试专属任务了
- 明确提测须知,比如提测任务里的需求一定要全部变为待提测;提测信息必须写清楚测试点和期望上线日期等。
- 目前TAPD里暂不支持对自定义任务进行甘特图绘制,因此单独维护了一份提测任务甘特图

5.3 效果
四、沉淀管理
1. 测试用例
1.1 背景
产品和项目的区别在于,一个产品可能需要好几个项目的支持,其中每个项目只支持部分模块。作为私有化的 项目交付时候,有可能需要导出一些测试用例进行交付。以往的时候用Excel管理测试用例,就意味着需要维护 很多份测试用例。线下传递,或者网盘上传,或者因为外包同学权限不够无法使用企业微信的腾讯文档。
TAPD测试用例启用之后,在线保存测试用例集,关联到需求上,支持大家自定义筛选、导出。可以查看一个 用例关联了多少的Bug,由此进一步确定测试用例集的等级。
1.2 效果

2. wiki
2.1 背景
现在有很多文档沉淀工具,比如公司层面的iwiki、KM、腾讯文档、网盘等。面向的对象不一样,场景不一样。
考虑到有部分外包同学参与项目,目前采用TAPD wiki,主要是以项目为维度,进行知识体系的沉淀, 包括日常的Retrospective和Showcase的记录、本TAPD项目的流程规约等等。
如果是文件比较大的一些资料包,则会上传到网盘。对于团队的沉淀,则会放在iwiki。对于个人知识和影响力的沉淀, 则会放在KM。
对于需要实时协作,还没落地的材料,则会选择腾讯文档,比如正在编写的架构设计方案。
2.2 效果

五、甘特图
1. 背景
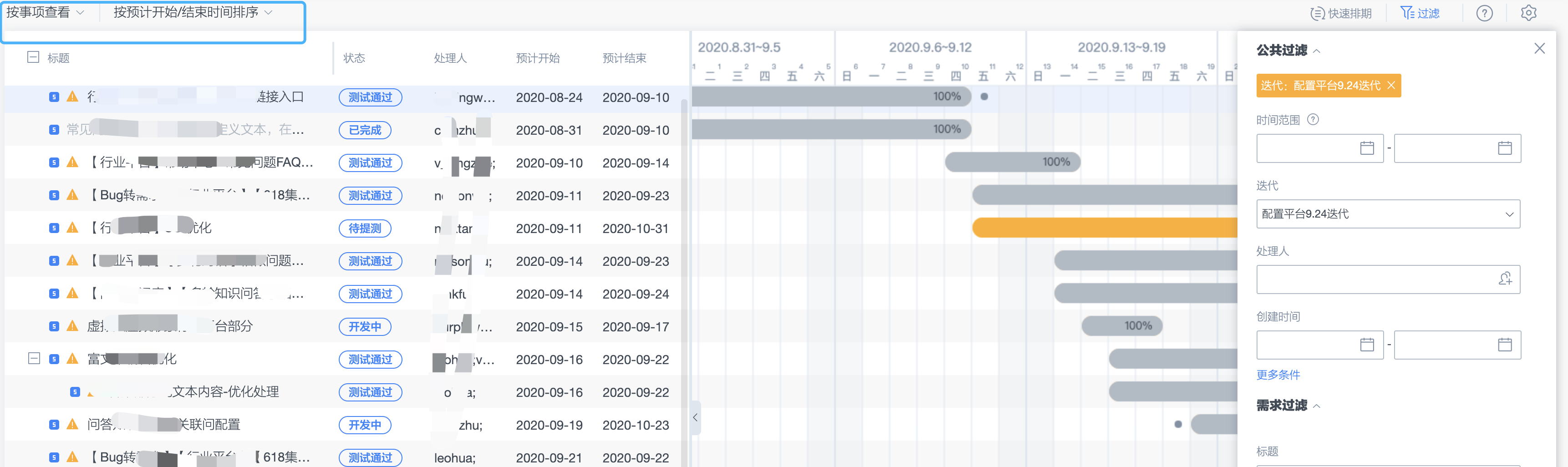
在跟进项目过程中,信息不对齐,信息过期是一个常见的问题。尤其是产品、开发各自维护一个自己版本的 项目进度Excel。将开发人员的预计开始时间、预计结束时间填写到TAPD的需求/子需求/任务上:
- 按照事项行查看,可获悉项目的整体进度,同时,在预计结束时间点附近,测试同学可询问是否提测, 以规划接下来的测试安排。
- 按照人力查看,可获悉某一个开发同学在某一天同时在几个任务上工作,工作负载情况等。
2. 效果
六、报表
1. 测试报告
1.1 背景
发送测试报告,比较常见的方式是发邮件,这就涉及到邮件模板,邮件归类,邮件归档保存了。在测试报告内容中, 如果需要列举出现的bug及其状态,需要手动copy或者导出,然后画表。
在TAPD报表里面启动项目报告,自定义模板,关联到本次提测的需求和缺陷,就可以省掉一部分编写邮件的时间, 同时只要在项目中的成员,哪怕是新人,都能看到历史所有的测试报告,不用一封封转发过去的邮件了。
1.2 效果
-
测试报告归档
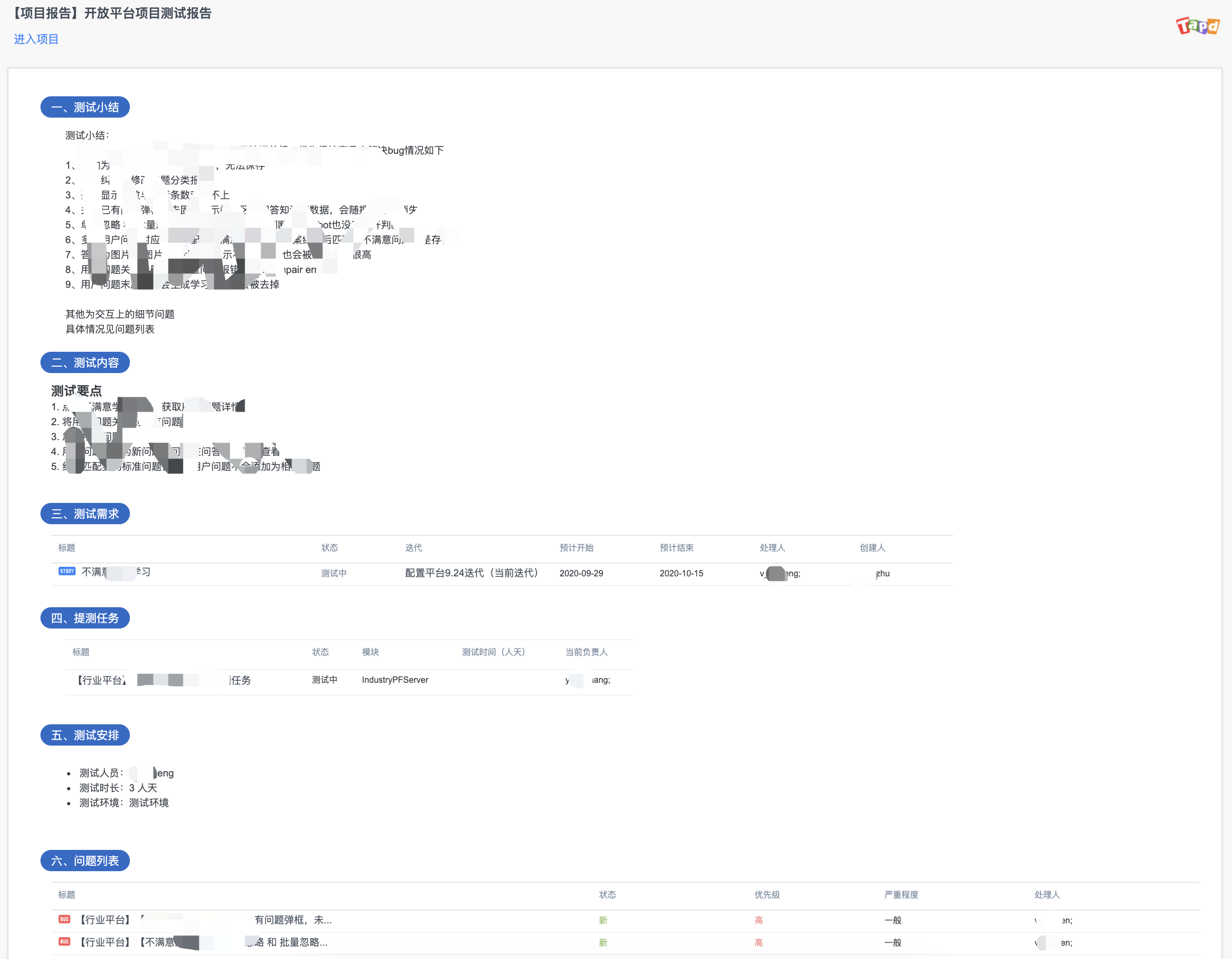
-
测试报告内容可直接关联需求、缺陷、提测任务
2. 统计
2.1 背景
所谓“一图胜千言”,数据可视化往往能将枯燥的文字等信息,转变成只管的图表,增加视觉冲击力。 在群里发一长段,当前的状态,最近的趋势,远不如一张数据图来的直观。
统计里面有缺陷类和需求类:
- 缺陷类经常被用来跟踪具体的缺陷,或者迭代末进行分析Bug 的ODC分析等
- 需求类经常用来查看迭代整体进度,EP趋势度量分析等
2.2 效果
-
缺陷统计-处于Open状态的Bug,可以用来跟进Bug
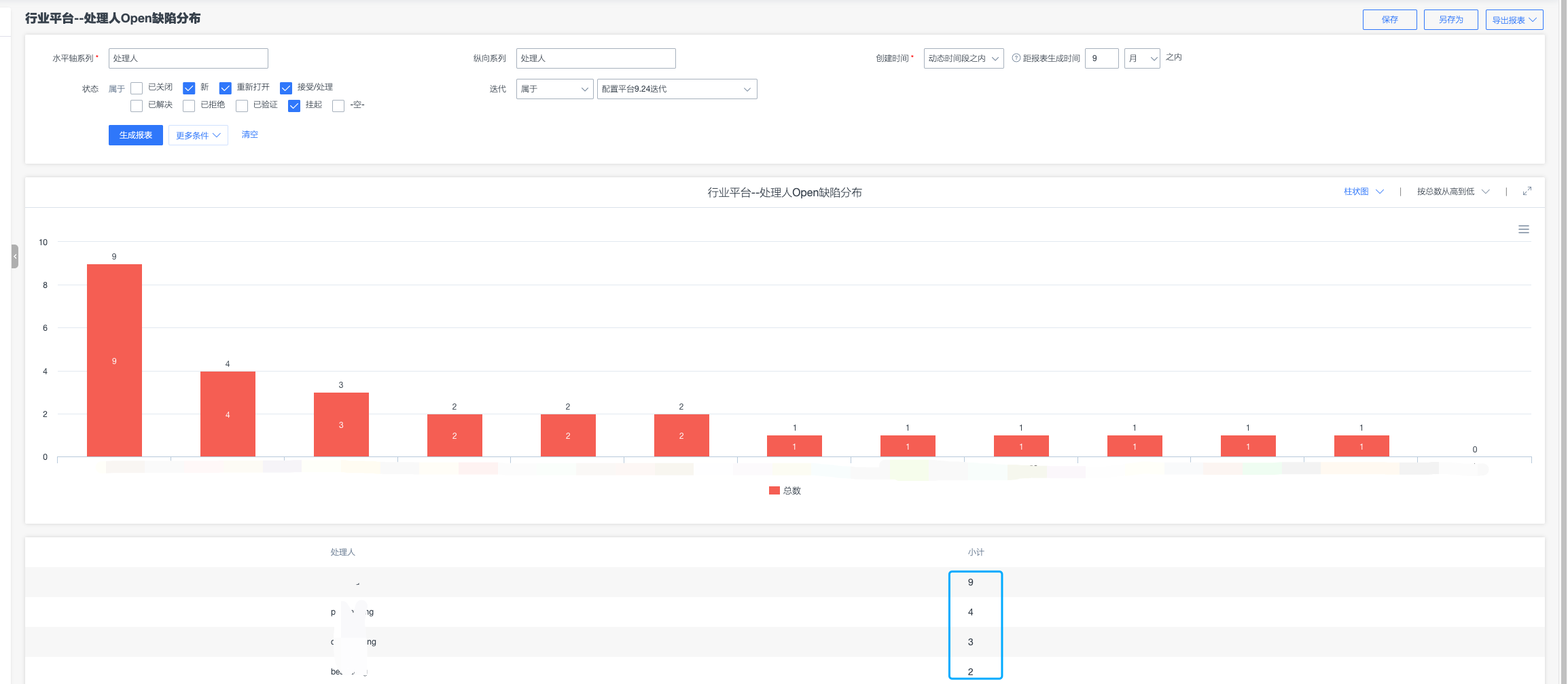
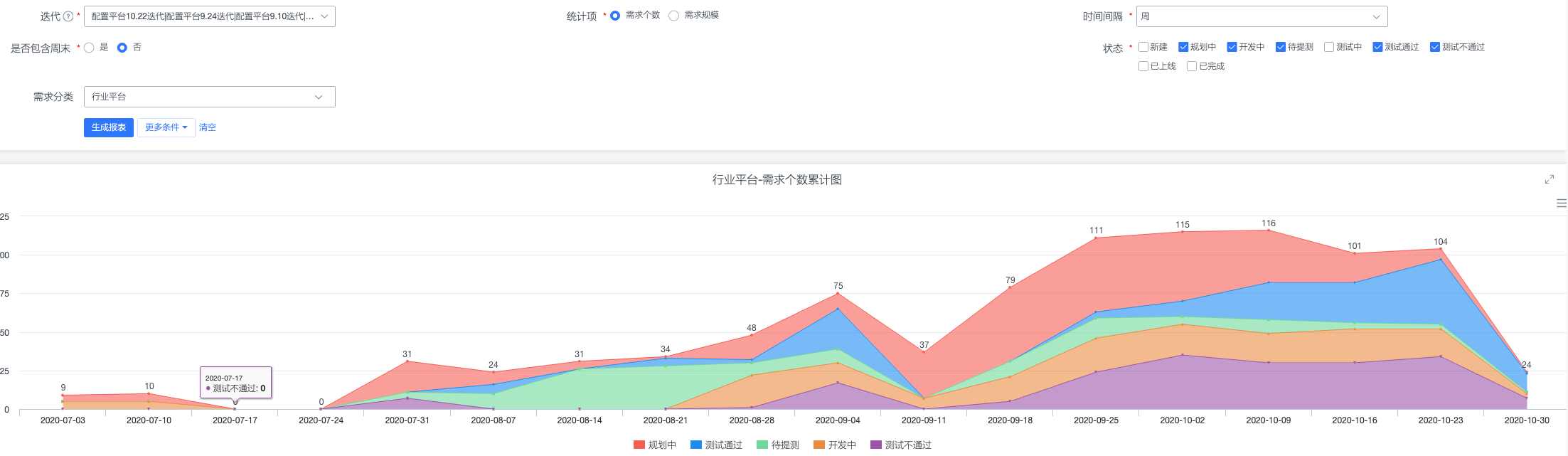
-
需求统计-需求个数趋势图,可用来查看项目一段时间的需求趋势
七、TAPD API度量体系
1. 问题
TAPD的报表能满足项目大部分的日常需求,但是暂未支持对于多个项目的横向对比、整体统计;暂未支持对 自定义任务的图表创建;或者无法满足有业务含义的定制类统计。
在推进EP实践过程中,有两个重要的指标:需求的LeadTime和迭代的Velocity,需要手动获取需求的各个 字段,进行一定的逻辑计算,画图。
-
Leadtime分为:
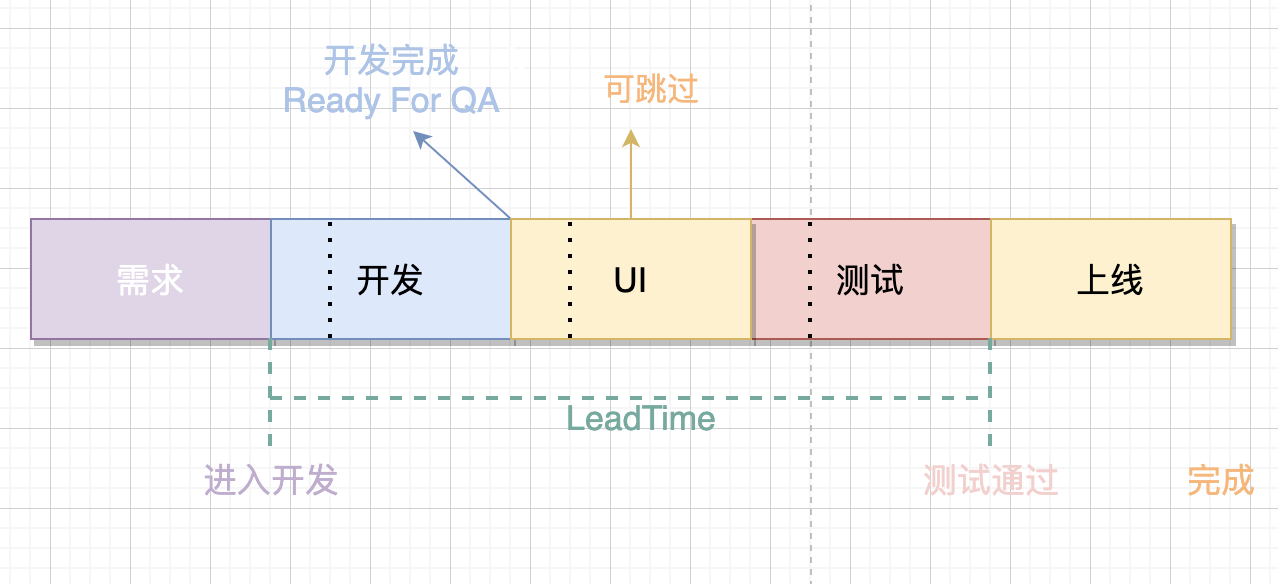
- 需求总体Leadtime = 测试通过时间 - 进入开发时间
- 需求的开发LeadTime = 待提测时间 - 进入开发时间
- 需求的测试LeadTime = 测试通过时间 - 进入测试时间
-
Velocity分为:
- 每个迭代,粗略的预计开发时间
- 将预估时间转换为归一化的Story Point
2. 解决思路
- 调用TAPD Open API,获取需求上的各个属性,比如status、story_change等
- 经过业务逻辑计算处理,存入到数据库
- 利用Grafana绘图
下面是一段调用API,然后生成原始数据的过程:
def get_story_changes_map(workspace_id, iteration_map):
count = get_story_count(workspace_id)
print('本 {} 下需求数为:{:d}'.format(workspace_id, count))
page = math.ceil(count / 50)
story_changes_map = {}
for cur in range(1, page + 1):
infos_by_page = get_story_map_by_page(workspace_id, cur)
story_ids_by_page = []
for info in infos_by_page:
story = info['Story']
story_changes_map[story['id']] = Story(story['id'], story['parent_id'],
story['status'],
story['category_id'],
story['iteration_id'],
(iteration_map[story['iteration_id']]
if story['iteration_id'] in iteration_map else ''),
story['created'],
story['completed'],
story['effort'])
story_ids_by_page.append(story['id'])
change_infos_by_page = get_story_changes(workspace_id, story_ids_by_page)
analyse_story_change(change_infos_by_page, story_changes_map)
sorted(story_changes_map.keys())
set_leaf_stories(story_changes_map)
# set_story_points(story_changes_map, workspace_id)
return story_changes_map
3. 效果
3.1 需求LeadTime
从最左边,刚刚开始统计的时候,状态挪动不明显,需求没有拆解,中间沟通信息不完善,到后面EP实践的推进,可以初见成效,看到需求整体LeadTime的减小。 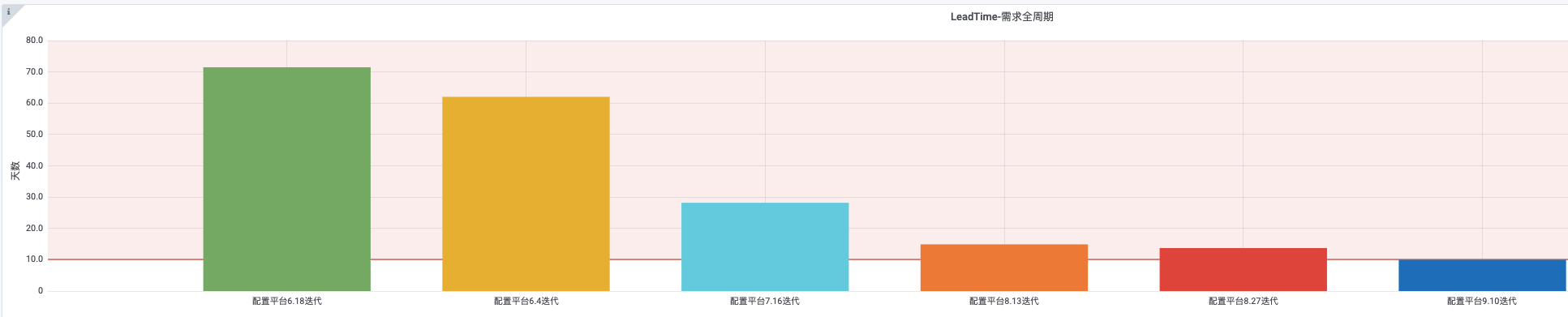
3.2 Velocity-故事点
从最左边开始,需求任务进行预估时间,进行排期,到后面任务的拆解、更细致管理,可以看到每个迭代的容量逐步提升。 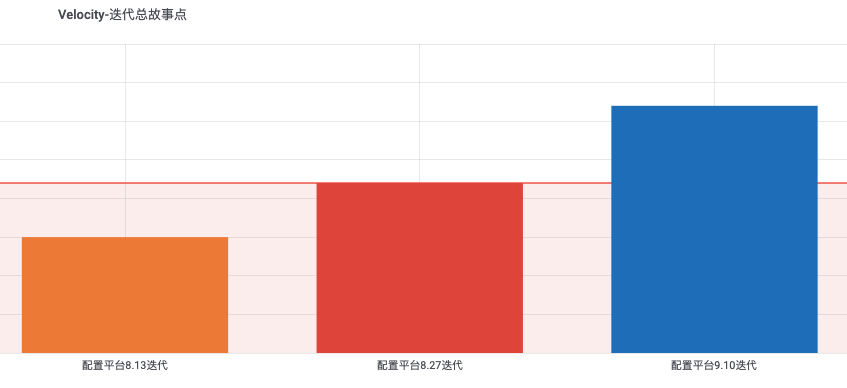
3.3 跨项目线上问题分布
跨多个TAPD项目,进行问题的归类分析。 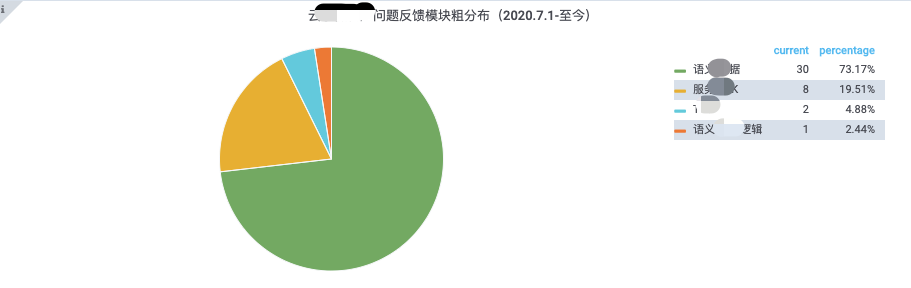
八、小结
有人会问,我也是用的TAPD,为什么和你的TAPD长的不一样?诚然,对于TAPD工作流的设置,功能的启用,每个团队 都有每个团队不一样的痛点,或者使用场景。在调研了质量部负责不同项目的同学之后,本文结合自身实践,列举了一些 共性问题,不在于面面俱到,旨在抛砖引玉,希望读者能有所启发,欢迎讨论~