一、前言
每次项目上遇到MYSQL性能优化的点,涉及到索引的时候,我都会或多或少、零零散散地查一些相关的资料,解决当时的难题。
这些知识点,既不系统、也不能完全确保正确无误,于是把以前从书里面《数据库系统实现》、《收获,不止SQL优化》看到的有关于 SQL索引的知识点,进行整理如下。
这篇文章不会对具体优化的tips进行介绍,主要是从概念上介绍索引,以及其结构与原理,至于使用技巧则会另外找时间写一篇文章记录。
二、什么是索引
索引是为了加速对表中数据行的检索而创建的一种分散的存储结构。数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
索引是这样的一种数据结构: 它以一个或多个字段的值为输入,并能”快速地”找出具有该值得记录。 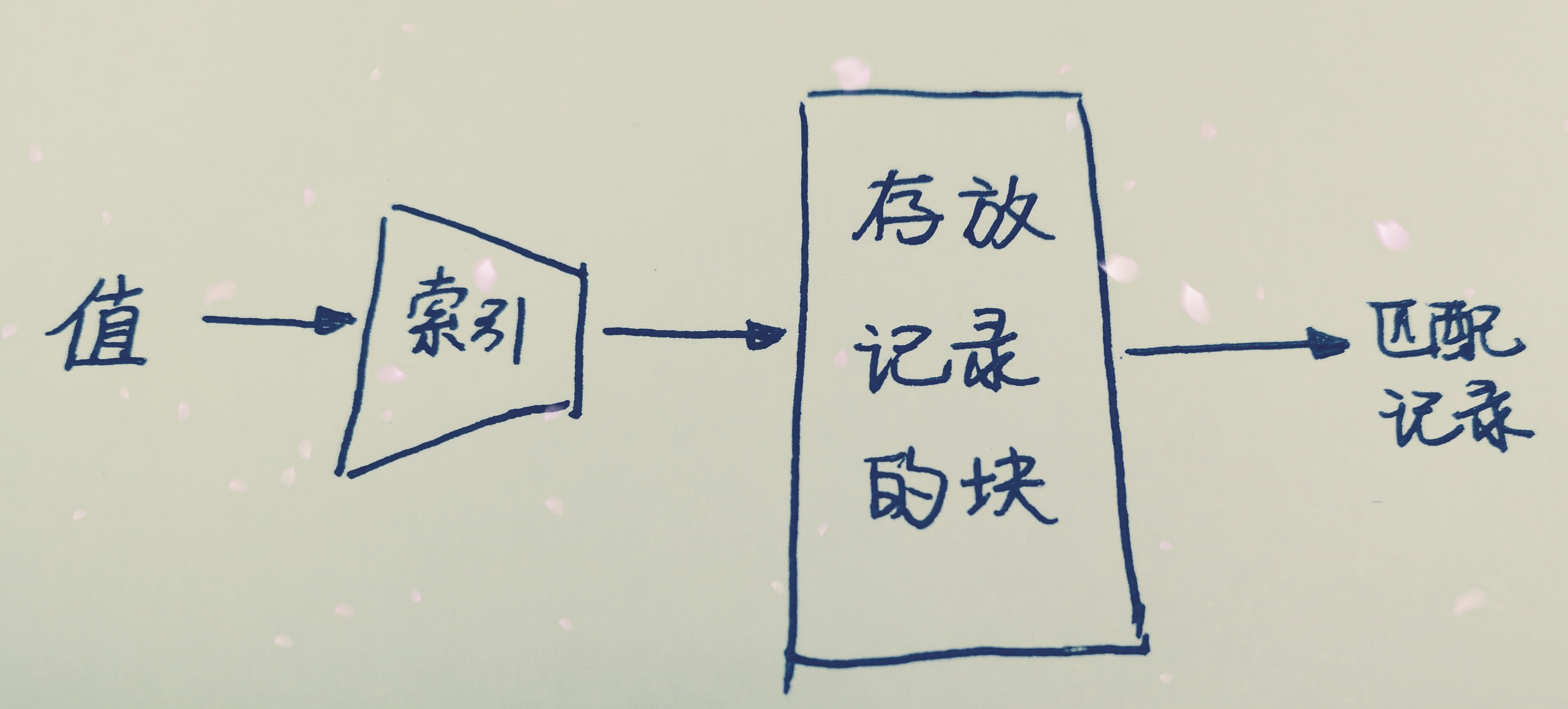
我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是 顺序查找(linear search),这种复杂度为O(n)的算法在数据量很大时显然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法, 例如二分查找(binary search)、二叉树查找(binary tree search)等。 如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于 二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外, 数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。 这种数据结构,就是索引的本质。
三、索引的优缺点
1. 优点
- 通过创建唯一索引,能够在索引和信息之间形成一对一的映射式的对应关系,增加数据的唯一性特点。
- 能提高数据的搜索及检索速度,符合数据库建立的初衷。
- 能够加快表与表之间的连接速度,提高数据的参考完整性。
- 在使用分组及排序子句进行时,能有效的减少检索过程中所需的分组及排序时间,提高检索效率。
- 在信息查询过程中可以使用优化隐藏器,提高整个信息检索系统的性能。
2.缺点
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
- 索引需要占物理空间。
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度。
四、索引的分类
MYSQL支持多种搜索引擎,每种引擎支持的索引类型不一样,这里只是从大而全的方面进行分类,不涉及到具体的搜索引擎。
1. 从数据结构上
- B+Tree
- HASH索引
- R-Tree索引(空间索引)
- FULLTEXT索引
2. 从物理存储上
- 聚集索引(主索引)
- 非聚集索引(辅助索引) 数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同,则为聚集索引;反之,则为非聚集索引。
3. 从逻辑角度上
- 普通索引(单列索引)
- 复合索引(多列索引)
- 主键索引
- 唯一索引
4. 从保存方式上
- 顺序索引
- 散列索引 顺序索引,是基于值的顺序排列;散列索引,是基于将值平均分布到若干散列桶中,一个值所属的散列桶是由一个散列函数决定的。
5.其他
- 稀疏索引
- 稠密索引 稠密索引中文件中的每个搜索码值都对应一个索引值;稀疏索引中,只为索引码的某些值建立索引项。二者皆为聚集索引。
非聚集索引(辅助索引)总是稠密索引。谈论一个稀疏索引的辅助索引是无意义的,因为辅助索引不影响记录的存储位置,我们也就不能根据 它来预测键值不在索引中显示指明的任何记录的位置。
五、索引的结构及原理
下文并没有按照上述的分类进行介绍,而是按照一定的顺序,通过多级索引引出常用的B+树索引,通过辅助索引中的间接引出散列索引。
1. 顺序文件
顺序文件是一种简单的文件组织,其产生方式是将数据文件按照某个排序键排序,并在该文件上建立索引。
2. 稠密索引
稠密文件为数据文件的每个记录设一个键-指针对。 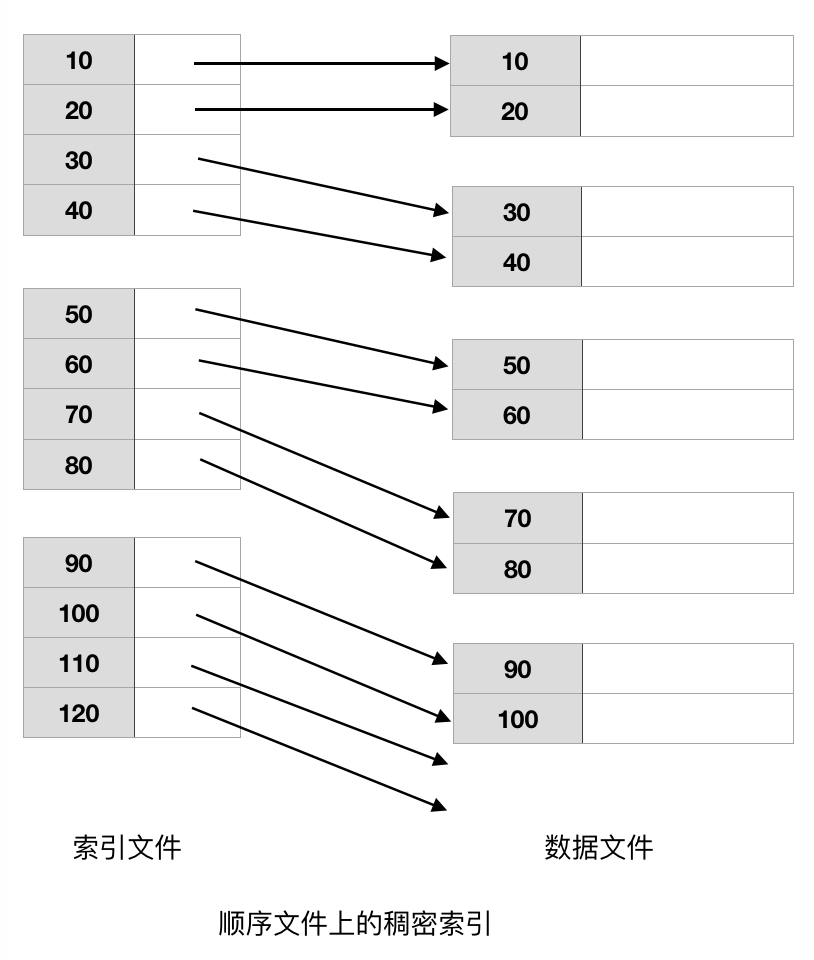
3. 稀疏索引
稀疏索引职位数据文件的每个存储块设一个键-指针对,它比稠密索引节省了更多的存储空间,但查找给定的记录需要更多的时间。 只有当数据文件是按照某个查找键排序时,在该查找键上建立的稀疏索引才能被使用,而稠密索引则可应用在任何的查找键。 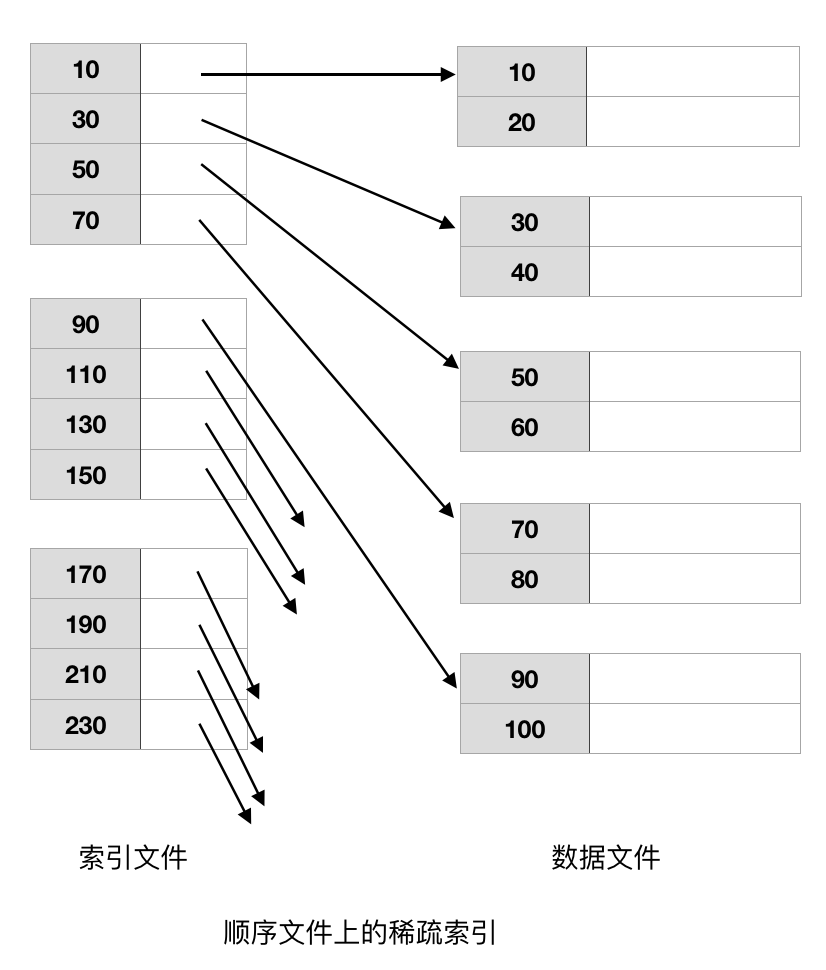
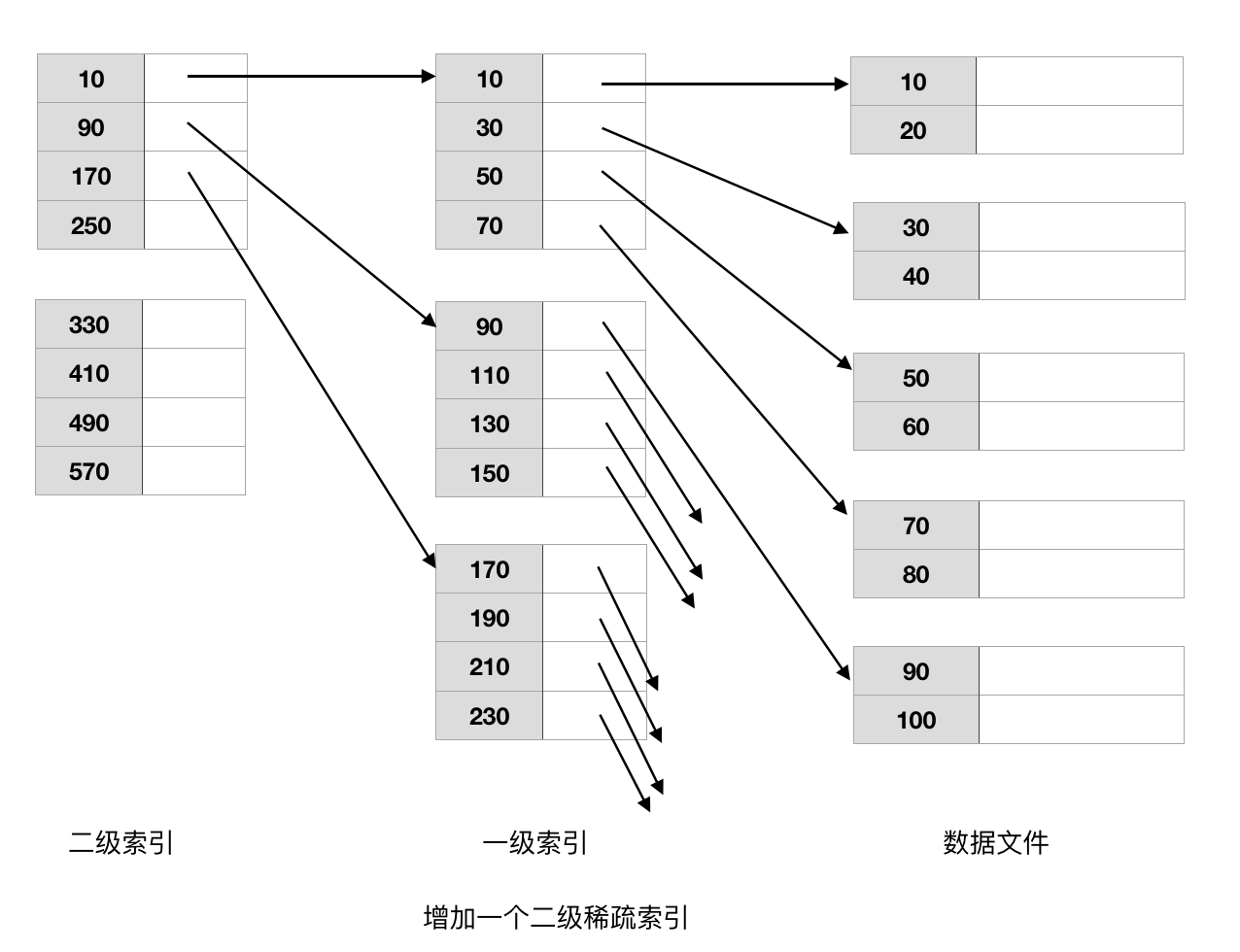
4. 多级索引
索引文件可能占据多个存储块,即便我们能定位索引存储块,并且能够使用二分法找到所需索引项,我们仍可能需要执行多次I/O操作才能获取所需记录。 通过在索引上再建索引,我们能够使第一级索引的使用更有效。二级或者更高级的索引必须是稀疏的,因为一个索引上的稠密索引将需要和其前一级索引 同样多的键-指针对,即同样的存储空间。 然而,这种做法有它的局限,与其建立多级索引,我们宁愿考虑下文中的B-树。
5. 非聚集索引(辅助索引)
非聚集索引并不决定数据文件中记录的存放位置。 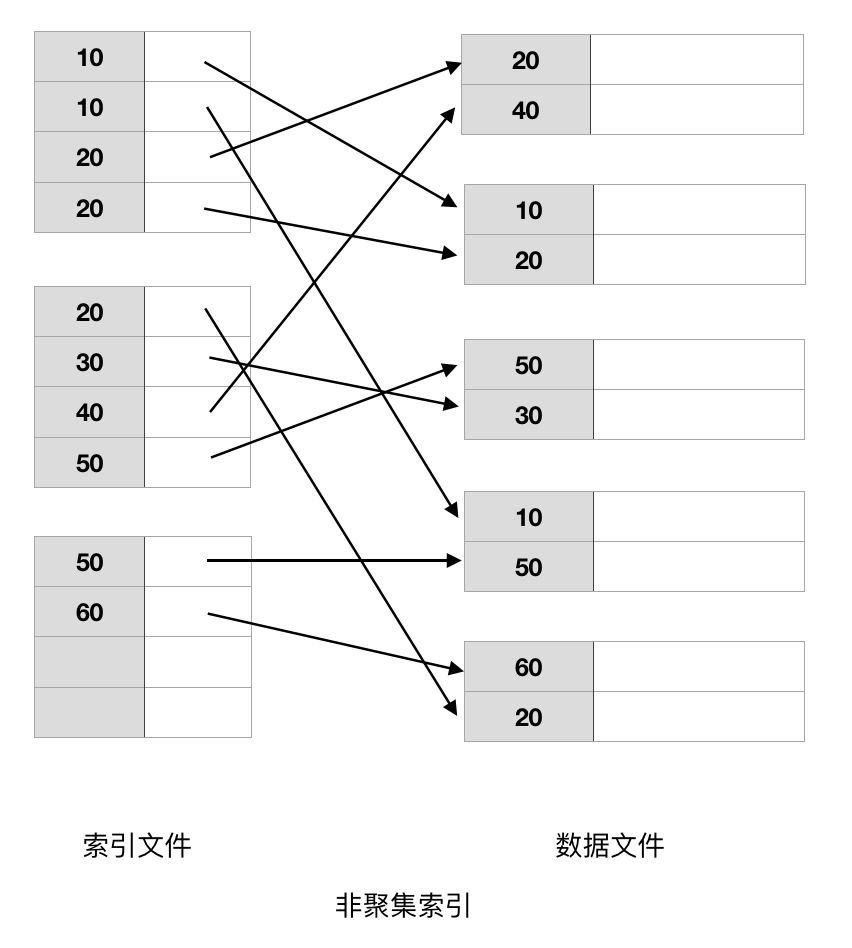
6. 非聚集索引(辅助索引)中的间接
上图所示结构存在空间浪费,假如某个索引值键在数据文件中出现n次,那么这个键值在索引文件中就要写n次,好的做法是只为指向该键值的所有 指针存储一次键值。
避免键值重复的一种简便方法是使用一个称为桶(Bucket)的间接层。
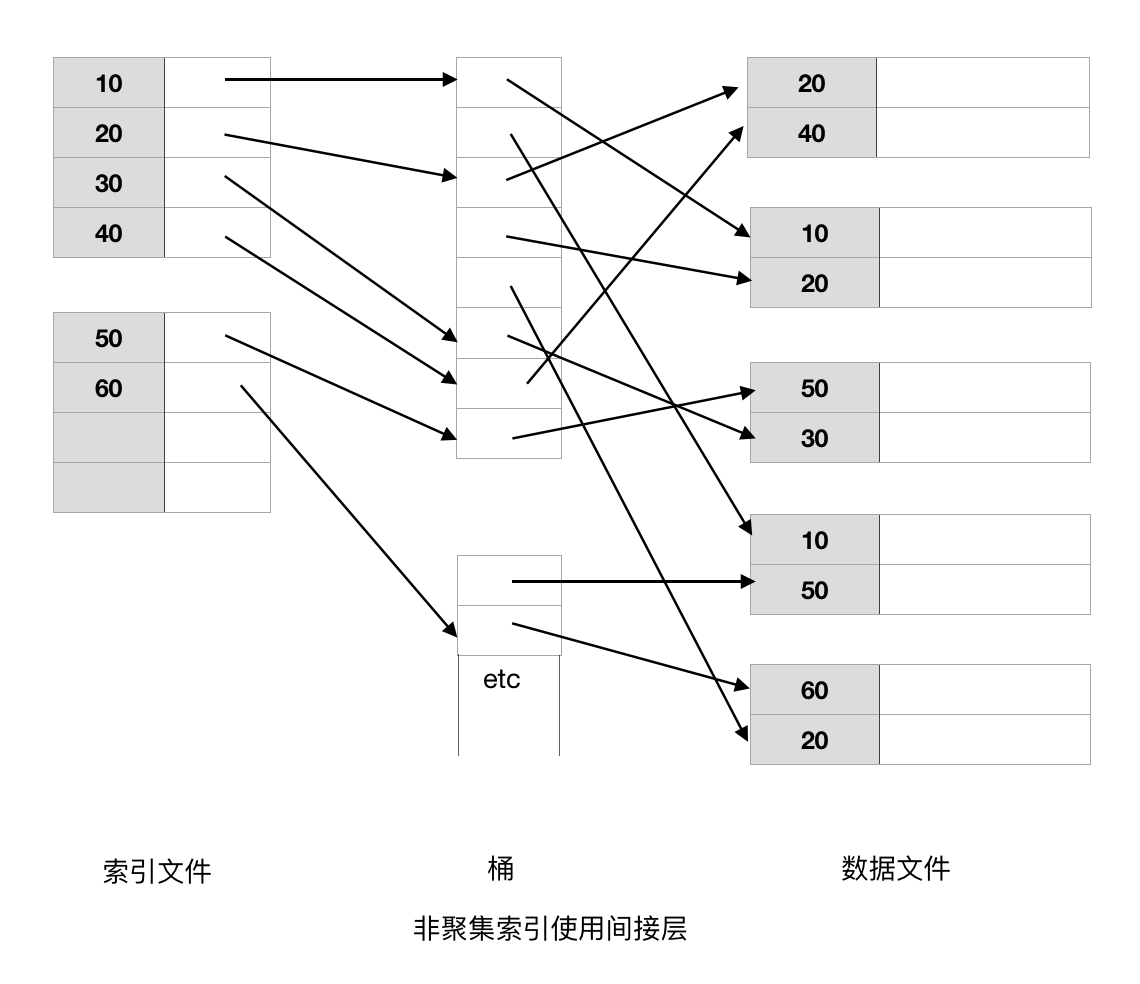
此外,该间接层还有另外一个好处,我们可以在不访问数据文件的前提下,利用桶的指针帮助回答一些查询。比如,查询多个条件时, 若每个条件都有一个可用的辅助索引,我们可以再主存中将指针集合求交来找到满足所有条件的指针,然后只需要访问检索交集指针所指向为记录, 节省了I/O开销。
为了构造间接层,我们可以通过构造一个散列函数,也即是下文的散列索引。
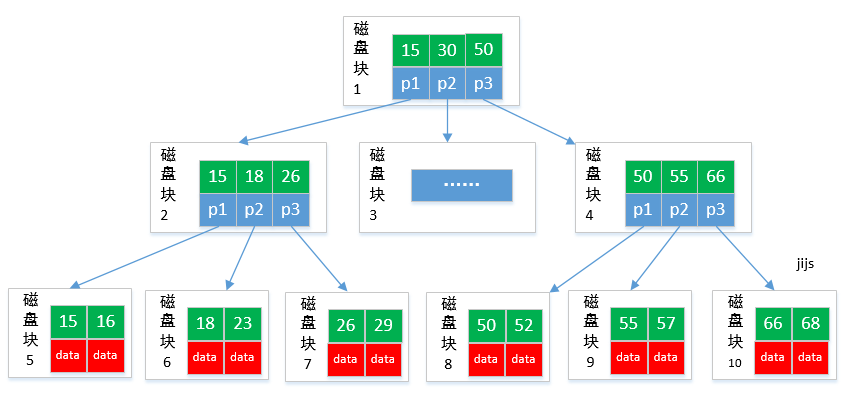
六、B树索引
在讲述B树之前,我们思考下几个问题:
- 数据库索引为什么使用树存储结构呢? 本文开头大致说明了索引的本质,由此我们知道原因是因为树的查询效率较高。
- 我们为什么不直接使用二叉树查询呢? 上文提到二叉树数据本身的组织结构不可能完全满足各种数据,其次是因为二叉树索引树的高度较大,最坏情况下读取磁盘IO次数较多。
那么为了减少磁盘IO,我们可以把原本”瘦高”的树结构变得”矮胖”,这就是B树的特征之一。
1. B-树
B-树,即B树,不能读成”B减树”。 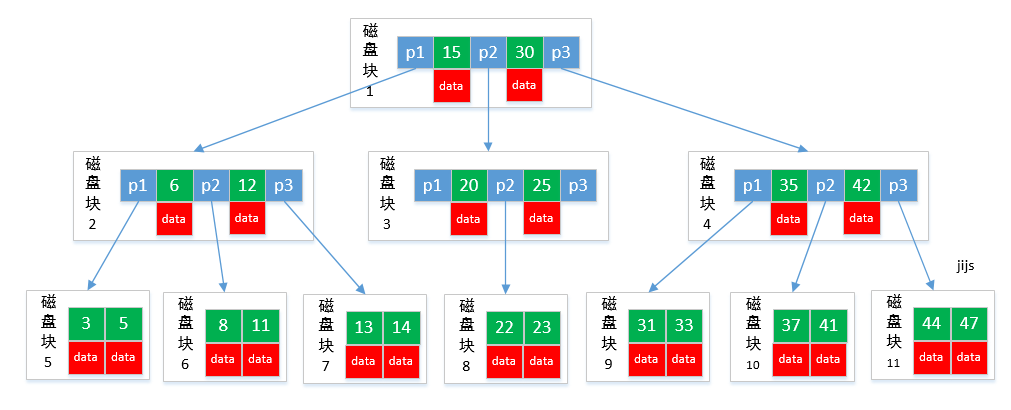
2. B+树