一、前言
知识图谱(Knowledge Graph)以结构化的形式描述客观世界中概念、实体及其之间的 关系, 将互联网的信息表达成更接近人类认知世界的形式,提供了一种更好地组织、管理和 理解互联网海量信息的能力。
知识图谱是人工智能重要分支知识工程在大数据环境中的成功应 用,知识图谱与大数据和深度学习一起, 成为推动互联网和人工智能发展的核心驱动力之一。对知识图谱的构建和理解是AI从业者的一个专项内容。
二、背景
想来所在的大团队一直都是AI相关,有涉及教育、文旅、智能客服等多个方面,其AI评测的核心技能, 我一直以来处于一个外来者,不甚了解。偶尔看了看旁边同事分享的文章,涉及到机器学习、NLP等等, 都只是蜻蜓点水大致走马观花了解一下。
这一次正好,接了知识图谱平台测试,以扫盲的心态先去整体了解,先有一个体系,之后便于逐步清晰明确细节。
三、定义
1. 知识
从数据到信息,再到知识,是不断加工、提取、抽象归纳的过程。 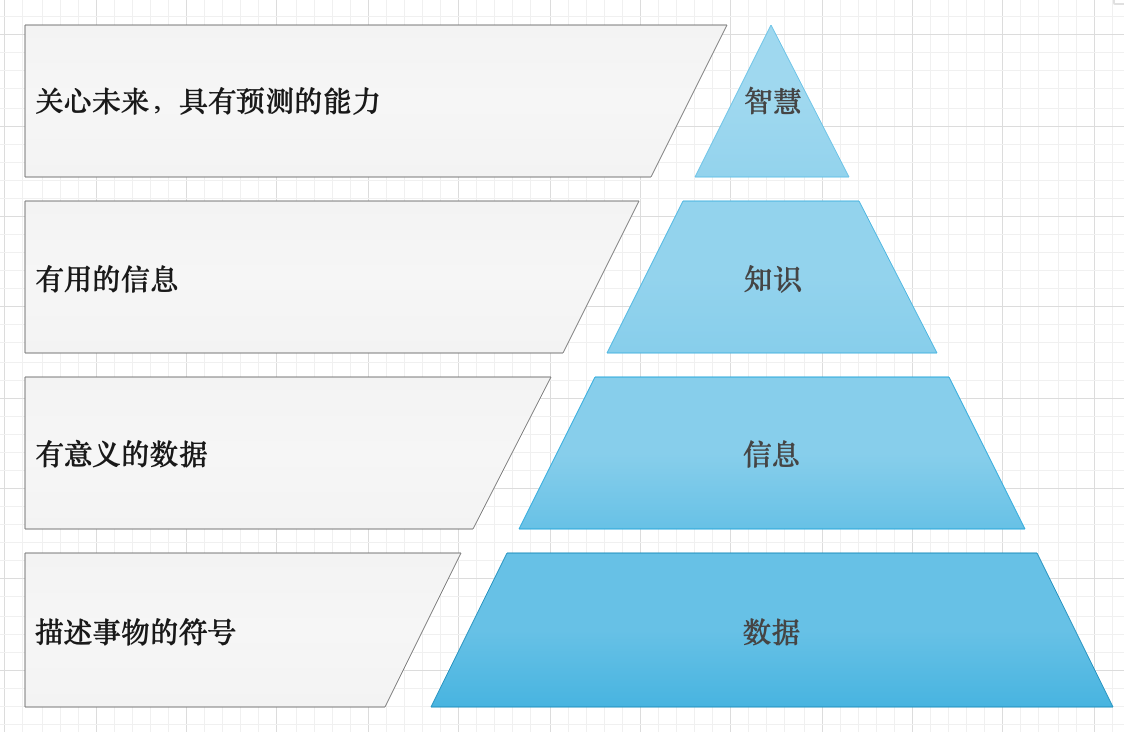
2. 图谱
知识图谱(Knowledge Graph,简称KG),由Google在2012年5月提出,初衷是希望借助网络多源数据 构建的知识库来增强语义搜索的效率和质量。其主要作用在于以结构化的方式来描述客观世界实体间的复杂关系。 通过在信息与信息之间建立联系,人类更加容易获取自己所需要的知识。
知识图谱,是一种大型的语义网络,是一种基于图的数据结构,由节点(Point)和边(Edge)组成。
3. 组成
知识图谱的基本元素三元组(SPO,Subject、Predicate、Object),由实体、属性、关系构成。
- <实体,关系,实体> e.g. 刘德华 - 妻子 - 朱丽倩
- <实体,属性,属性值> e.g. 刘德华 - 出生日期 - 1969年9月27日
4. 分类
知识图谱的分类方式很多,例如可以通过知识种类、构建方法等划分。从领域上来说, 知识图谱通常分为通用知识图谱和领域知识图谱:
通用知识图谱:通用知识图谱可以形象地看成一个面向通用领域的“结构化的百科 知识库”, 其中包含了大量的现实世界中的常识性知识,覆盖面极广。 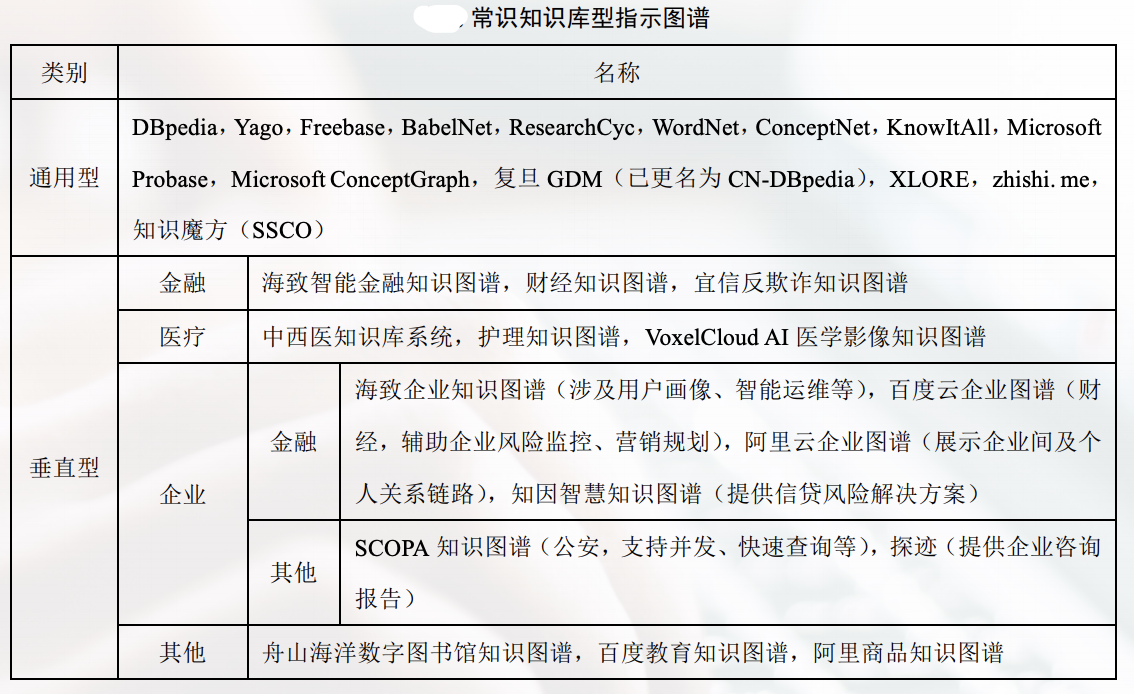
特定领域知识图谱:领域知识图谱又叫行业知识图谱或垂直知识图谱,通常面向某 一特定领域, 可看成是一个“基于语义技术的行业知识库”。
四、历史

第一阶段是60年代前后,知识图谱的萌芽期。 那是一个人工智能大跃进的时代,AI的科学家认为不出10年就会实现人工智能。1956年一群世界顶级科学家聚在 一起讨论机器模拟人的智力,但是并没有实质性进展,却诞生了“人工智能”这个词。这个时期以后, 人工智能成为了专门的研究领域。同时,伴随着人工智能的定义,出现了第一批人工智能系统,并且有专门的 一个统称“专家系统”。其中一些代表性的专家系统,比如Baseball、LUNAR、DENDRAL等。
第二阶段是90年代前后,知识图谱的发展期。 80年代开始,”机器学习“发展的如火如荼。 所有人都希望机器可以通过数据自动学习,并达到智能水平。虽然机器学习取得了一定的成果,但是并没有达到 所谓的智能水平。于是人们更加理性的看待机器学习,认为机器学习需要人工的知识进行复制, 于是提出了Ontology和 Semantic Web这些概念。最早Ontology其实是哲学范畴, 我们不需要深究,1991年这个词被引入到计算机领域,辅助计算机做一些理解世界的工作。 Semantic Web是伯纳斯-李(WWW的提出者)提出的。人们称WWW位web 2.0时代,主要是解决网页互联的问题, 诞生了google和baidu这样的大型搜索引擎公司。Semantic Web被称为web 3.0时代, 主要是解决机器对网页的理解。Ontology比较著名的系统有:Ontobroker、SKC和Agent等; 而Semantic Web比较著名的系统有TWINE等。
第三阶段是2006年之后,知识图谱的成熟期。 以Google为代表的搜索引擎公司,有着各式各样的 数据资源,如图谱、视频、网页、新闻等,但是这些资源却是割裂的,于是Google大神阿米特-辛格尔 提出了知识图谱这个项目,既可以吧所有的资源进行整合,又能够全民的了解摸个实体。开发者大会上 配上了经典的slogan:”Things, not strings”,引起了业界轩然大波,所有的公司都开始了 知识图谱的建设,这个阶段的代表系统比如:Freebase、Yago、NELL、Depedia等。
涉及到的名词:
-
专家系统,规模较小,一般是固定领域,由专家成员建设。例如:Baseball系统就是一个棒球的专家系统, 你可以询问比分,赛事等。
-
Ontology:本体,主要是建设实体的上位词概念之间的逻辑关系,以及概念之间的一些推理, 重心并不是建设实体以及实体关系;
-
Semantic Web:强调的是让机器如何更结构化的理解网页,而不是整个世界;
-
Knowledge Graph:面向全领域建设,主要由schema、entity和edge组成。 schema和ontology比较像,但是规模小很多,主要是起到约束entity的作用。
五、知识图谱技术
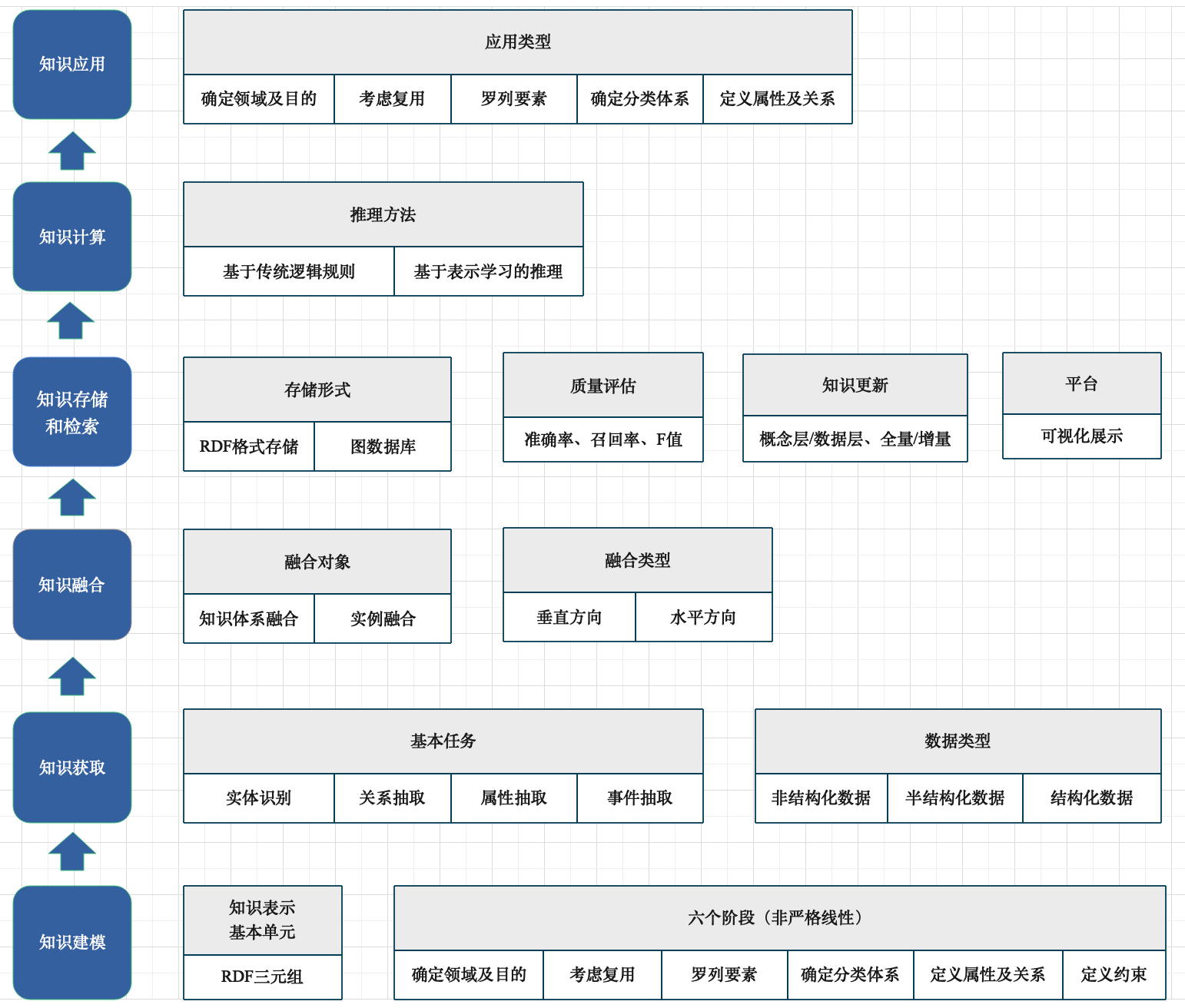
1. 知识建模
知识表示将现实世界中的各类知识表达成计算机可存储和计算的结构。知识表示技术变化,大致分为三个阶段:
-
基于符号逻辑进行知识表示和推理,主要包括逻辑表示法(如一阶逻辑、描述逻辑)、产生式表示法 和框架表示等。逻辑表示与人类的自然语言比较接近,是最早使用的一种知识表示方法。
-
随着语义网概念的提出,万维网内容的知识表示技术逐渐兴起,包括基于标签的半结构置标语言 XML、基于万维网资源语义元数据描述框架 RDF和基于描述逻辑的本体描述语言 OWL等,使得将机器理解和处 理的语义信息表示在万维网上成为可能,当前在工业界大规模应用的多维基于 RDF 三元组的表示方法。
-
随着自然语言处理领域词向量等嵌入(Embedding)技 术手段的出现,采用连续向量方式来表示知识的 研究(TransE 翻译模型、SME、SLM、NTN、 MLP,以及NAM 神经网络模型等)正在逐渐取代与上述 以符号逻辑为基础知识表示方法相 融合,成为现阶段知识表示的研究热点。
2. 知识获取
信息抽取,是指从原始数据中提取对业务有用的知识。
原始数据:
- 非结构化数据(Free Text)
- 半结构化数据(Semi-Structured)
- 结构化数据(Structured)
有用的知识:
- 实体(Entity)
- 关系(Relation)
- 属性(Attribute)
- 事件(Event)
信息抽取在学术上一般使用自然语言处理(NLP,Nartual Language Processiing)的方法,实践中也常常 结合规则的手段。针对不同的数据来源,信息抽取包含以下部分: 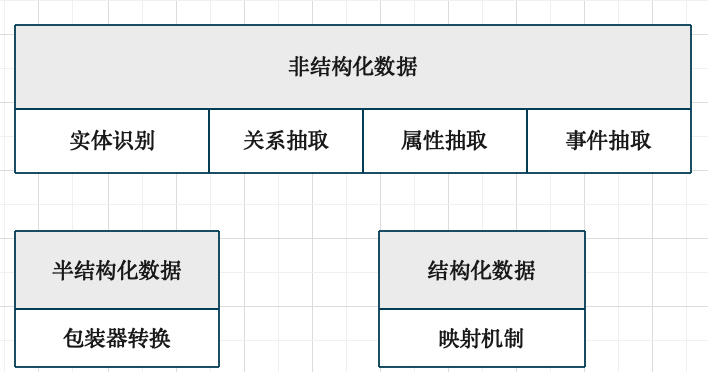
2.1 实体识别方法
- 传统统计模型方法,如最大熵分类模型、 SVM 模型、隐马尔可夫模型、条件随机场模型
- 深度学习方法,如NN-CRF
- 文本挖掘方法,从特定结构(如列表、Infobox)构建实体挖掘的特定规则。
2.2 关系抽取方法
- 限定域关系抽取和开放域关系抽取
- 基于规则的关系抽取和基于机器学习的关系抽取。基于规则的方法,是由通晓语言学知识的专家根据抽取任务的要求 设计出一些包含词汇、句法和语义特征的手工规则(或称为模式),然后在文本分析的过程 中寻找与这些模式相匹配的 实例,从而推导出实体之间的语义关系。基于机器学习的分为无监督关系抽取,有监督关 系抽取、弱监督关系抽取。
2.3 属性抽取
属性主要是针对实体而言的,以实现对实体的完整描述,由于可以把实体的属性看作实体与属性值之间的一种 名词性关系,所以属性抽取任务就可以转化为关系抽取任务
2.4 事件抽取方法
- 基于模式匹配,按照模式构建过程中所需训练数据的来源可细分为基于人工标注语料的方法和弱监督的方法。
- 基于机器学习,根据利用信息的不同可以分为基于特征、基 于结构和基于神经网络三类主要方法。
3. 知识融合
知识融合是对不同来源、不同语言或不同结构的知识进行融合,从而对已有知识图谱进行补充、更新和去重。
数据层融合:
- 实体解析(Entity Resolution, ER)
- 实体对齐 (Entity Alignment, EA)
- 实体链接 (Entity Linking, EL)
- 实体发现 (Entity Discovery, ED)
- 实体消歧 (Entity Disambiguation, ED)
- 指代消解(Coreference Resolution)
模式层融合:
- 概念合并
- 属性合并
- 关系合并
4. 知识存储
知识图谱的存储模型:
- RDF:XML等协议描述
- 属性图:有向图、带标签、有属性的多重图
知识图谱的存储方式:
-
RDF存储 RDF,Resource Description Framework,也称为三元组存储(Triplesotr),通过六重索引(SPO、SOP、PSO、 POS、OSP、OPS)的方式解决了三元数组搜索的效率问题
-
关系型数据库
关系型数据库一般可以采用三列表存储、水平存储、属性表存储的方式存储知识图谱数据,但随着实体属性的增长和关系的加深, 构建索引的开销昂贵,查询性能也严重下降。
-
图数据库 图数据库的结构定义相比RDF数据库更为通用,实现了图结构中的节点,边以及属性来进行图数据的存储,典型的开源图数据库就是Neo4j。
图数据库本身提供完善的图查询语言、支持各种图挖掘算法。在查询速度上要优于关系型数据库,特别是多跳查询的性能较好。 但是其缺点是图数据库的更新比较复杂,图数据库的分布式存储实现代价高,数据更新速度慢,大节点的处理开销很高。 所以一般使用以图数据库为主,结合其他系统的方式来存储知识图谱。
5. 知识计算
知识推理,指根据已获得的知识产生新的知识或者得出新的结论,或识别错误的知识。识别新的知识,可以拆解为链接预测、 实体预测、关系预测、属性预测等问题。
知识计算的方法:
- 图挖掘计算
- 知识推理
- 符号推理
- 统计推理
6. 知识应用
-
知识融合 当前互联网大数据具有分布异构的特点,通过知识图谱可以对这些数据 资源进行语义标注和链接,建立以知识为中心的资源语义集成服务。
-
语义搜索和推荐 知识图谱可以将用户搜索输入的关键词,映射为知识图谱中客观 世界的概念和实体,搜索结果直接显示出满足用户需求的 结构化信息内容,而不是 互联网网页。
-
问答和对话系统 基于知识的问答系统将知识图谱看成一个大规模知识库,通过理 解将用户的问题转化为对知识图谱的查询,直接得到 用户关心问题的答案。
-
大数据分析与决策 知识图谱通过语义链接可以帮助理解大数据,获得对大数据的 洞察供决策支持。
 )
)
六、架构
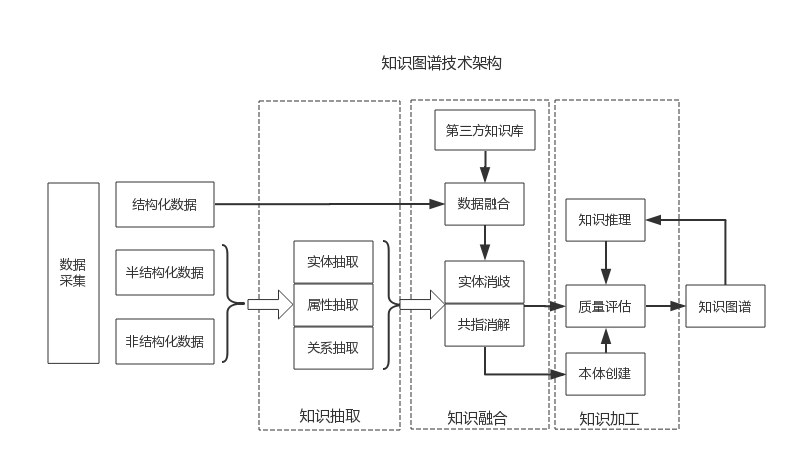
此架构图旨在将上述的步骤串联起来,至于具体在架构层面,针对不同的应用背景,可能稍有不一致的地方。