前言
在EP度量的过程中,各个维度的指标繁多,纷繁杂乱中,如何根据北极星指标,层层深入;优先关注团队目前的核心指标,度量分析;及时收集反馈,灵活调整呢?
数据下钻,本质是改变了数据的维度,转换了分析的粒度。本文是笔者在腾讯云小微EP数据透视过程中的一点探索和积累,基于Grafana平台进行数据下钻, 拨云见日,也希望能抛砖引玉,对有需要的同学有所启发,互相探讨。
注:本文的数据进行了一定的处理,不代表真实情况。
一、Grafana基本图形
说明: 柱状图、折线图、饼图等面板的每一条数据必须有时间序列。
1、柱状图
1.1 效果
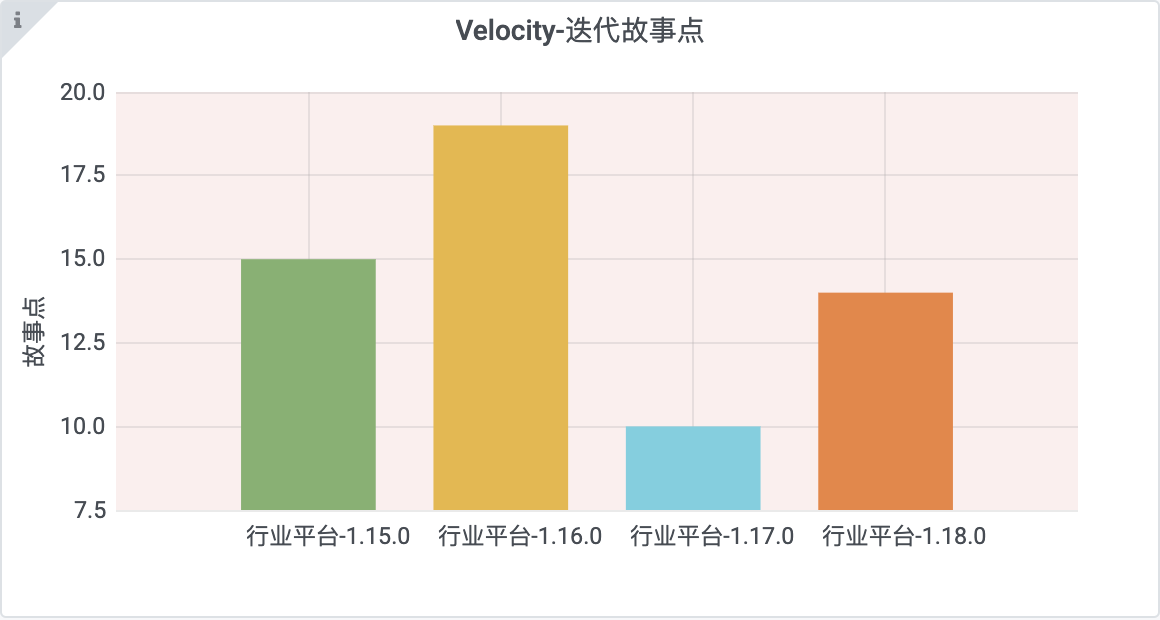
1.2 配置
- Visualization:选择Graph
- Display:开启Bars
- Axes:填写X轴Y轴相关信息,X-Axis的Mode选择Series
1.3 SQL
SELECT
now() time,
i.name,
SUM(s.size)
FROM
t_tapd_story_stage s
LEFT JOIN t_tapd_iteration i ON i.name = s.iteration_name
WHERE
s.completed_at <> ''
AND $__timeFilter(i.enddate)
GROUP BY
i.tapd_iteration_id
ORDER BY
i.tapd_iteration_id ASC
- Format as选择Time series
- $__timeFilter,将sql语句中where条件的时间段,替换成grafana中的用户自定义选择的时间段。
2、折线图
2.1 效果
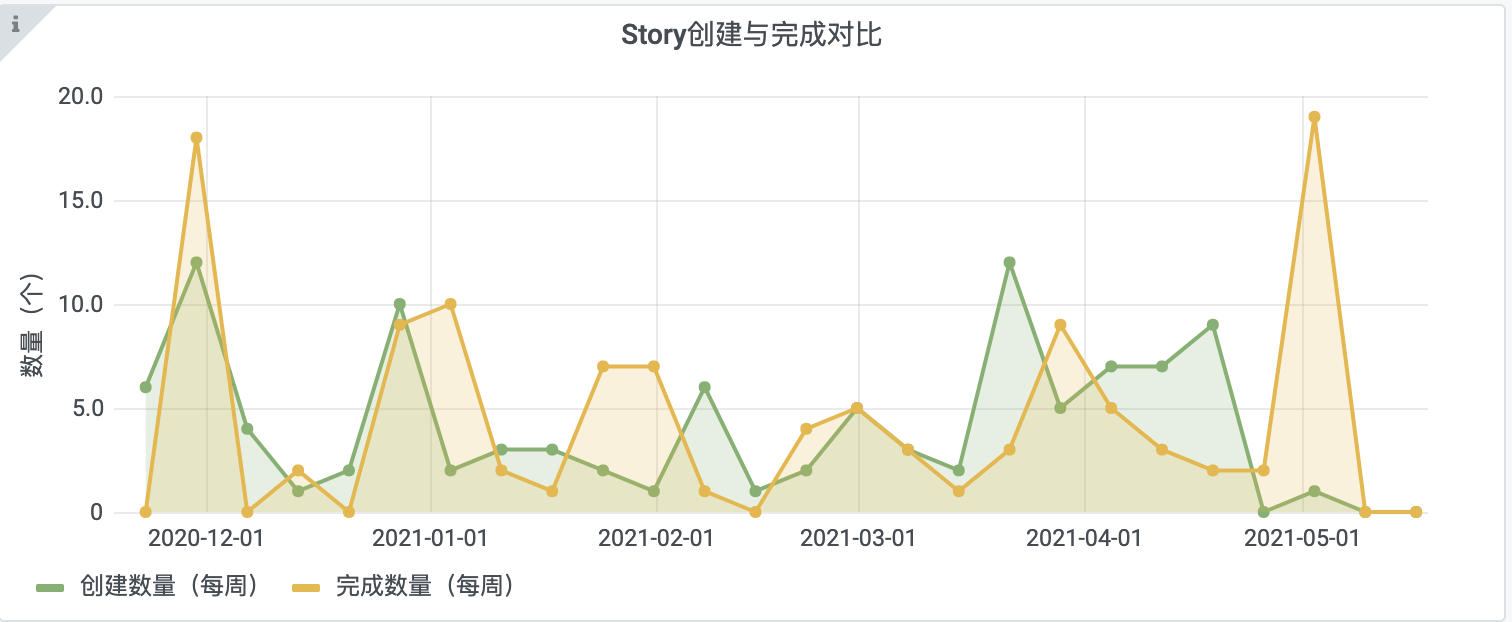
2.2 配置
- Visualization:选择Graph
- Display:开启Lines、Points
- Axes:填写X轴Y轴相关信息,X-Axis的Mode选择Time
2.3 SQL
SELECT
unix_timestamp(data_datetime) time,
(
SELECT
count(*)
FROM
t_tapd_story_stage
WHERE
created_at < date_format(data_datetime, '%Y-%m-%d')
AND created_at > DATE_ADD(date_format(data_datetime, '%Y-%m-%d'), INTERVAL -7 DAY)
) "创建数量(每周)",
(
SELECT
count(*)
FROM
t_tapd_story_stage
WHERE
completed_at < date_format(data_datetime, '%Y-%m-%d')
AND completed_at > DATE_ADD(date_format(data_datetime, '%Y-%m-%d'), INTERVAL -7 DAY)
) "完成数量(每周)"
from
t_calendar
WHERE
$__timeFilter(data_datetime)
and WEEKDAY(data_datetime) = 0
- 单独引入了一个专门写有时间的表t_calendar,进行取点
- WEEKDAY和INTERVAL -7 DAY配合,形成一周数据汇总
3、饼图
3.1 效果
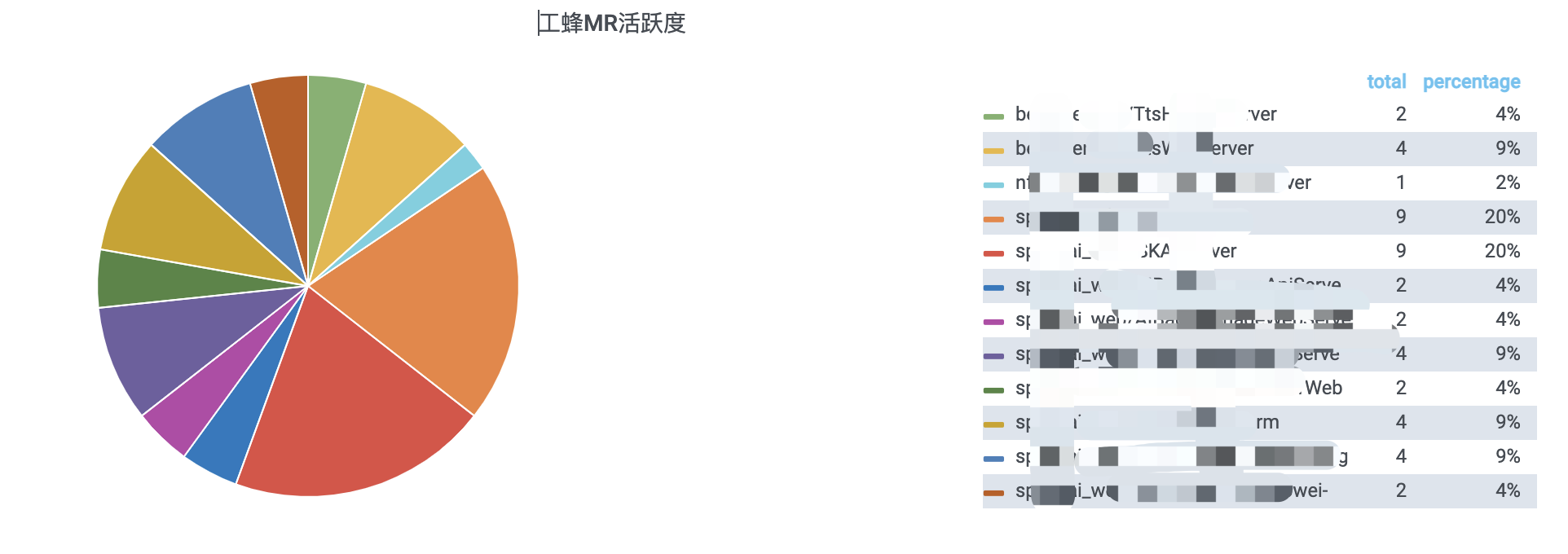
3.2 配置
- Visualization:选择Pie Chart
- Options:Type选择Pie,开启Show Legend,开启Show Percentage
3.3 SQL
SELECT
now() time,
project_path AS '仓库',
COUNT(*) AS 'MR数量'
FROM
t_git_merge_request
WHERE
$__timeFilter(created_at)
GROUP BY project_path
- Format as选择Time series
4、表格
4.1 效果
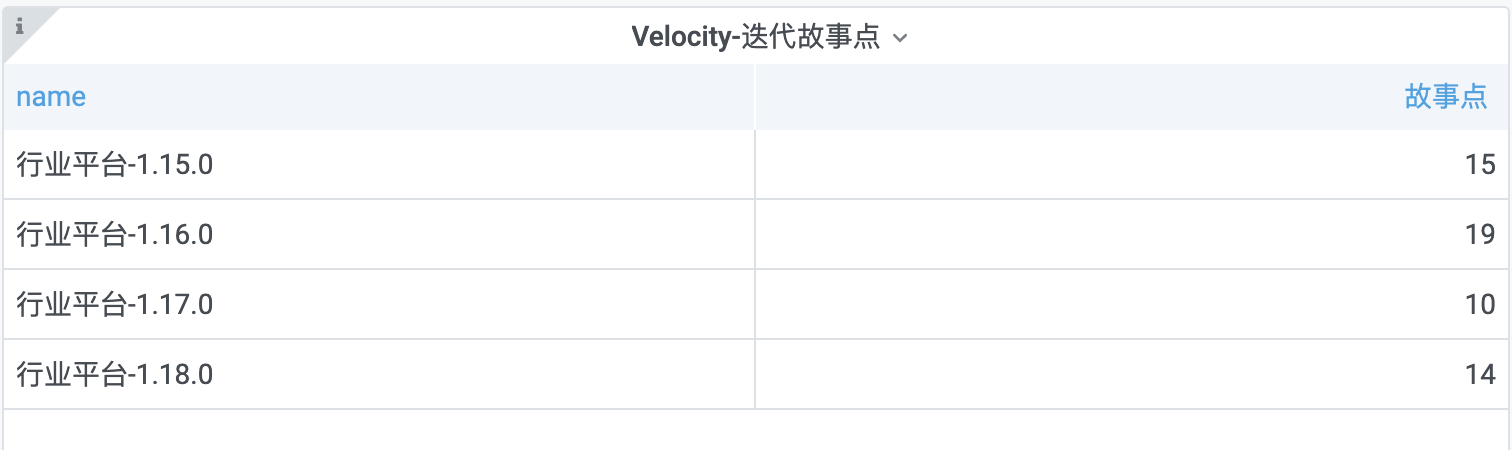
4.2 配置
- Visualization:选择Table
- Display:开启Show header
4.3 SQL
SELECT
i.name,
SUM(s.size) as '故事点'
FROM
t_tapd_story_stage s
LEFT JOIN t_tapd_iteration i ON i.name = s.iteration_name
WHERE
s.completed_at <> ''
AND $__timeFilter(i.enddate)
GROUP BY
i.tapd_iteration_id
ORDER BY
i.tapd_iteration_id ASC
- 本小节示例,是在1.1柱状图基础上进行修改而来
- Format as选择Table
5、单一状态图
5.1 效果
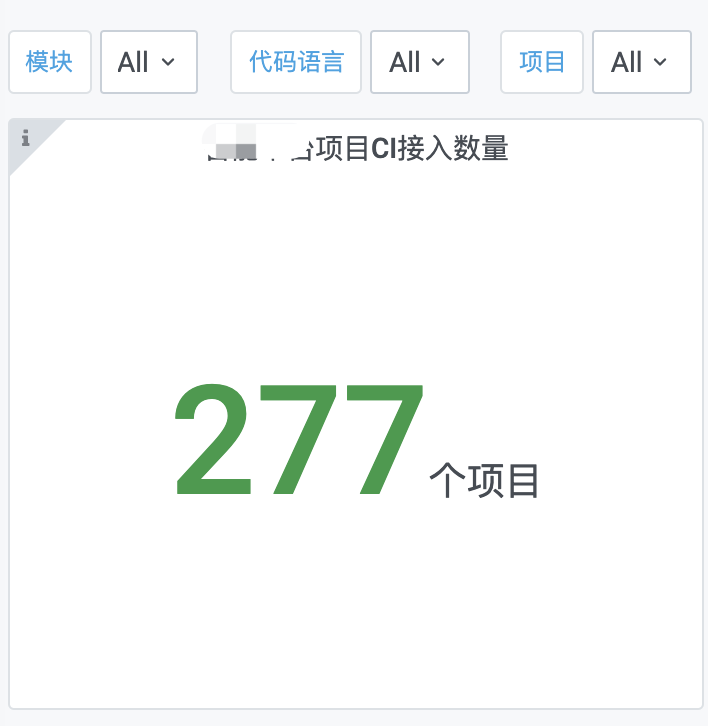
5.2 配置
- Visualization:选择Stat
- Options:Value部分,在Postfix加上后缀“个项目”,可调整字体大小;在Coloring部分可调整颜色
5.3 SQL
SELECT
COUNT(DISTINCT t_pipeline.server_name) qci_prj_cnt
FROM
t_pipeline,
repo,
t_component
WHERE
t_pipeline.server_name = repo.server_name
AND t_component.name=repo.component
AND t_component.name in ($ep_component)
AND repo.code_language in ($ep_code_language)
AND locate($ep_sp_project, repo.projects)
- 里面用到了变量,将在下文原子操作之变量部分讲解
- Format as选择Table
6、仪表盘图
6.1 效果
可以画一个或者多个仪表盘,下图为多个示例:
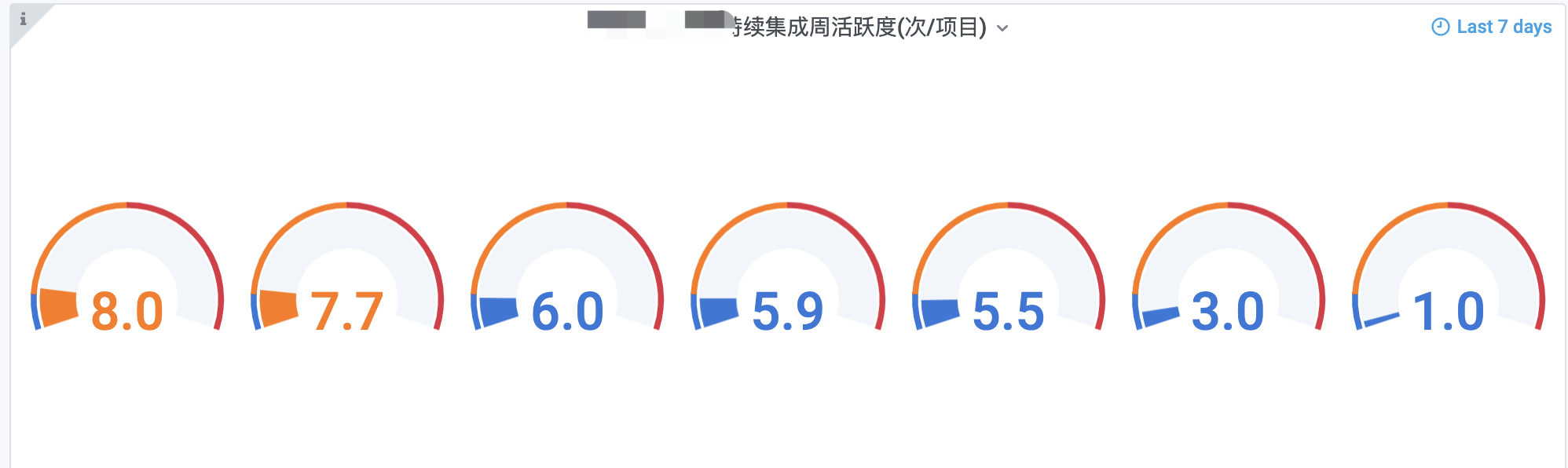
6.2 配置
- Visualization:选择Stat
- Display:开启Show threadhold markers
- 在Field标签页,可以配置Thresholds,配合上述Display使用
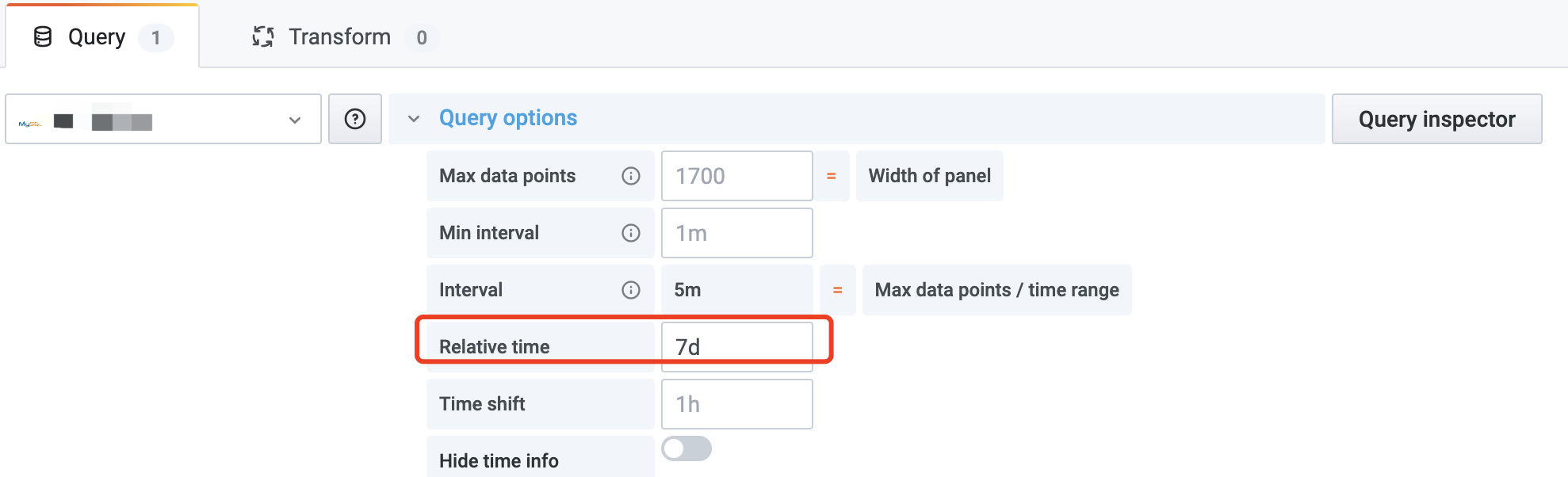
- 注意到效果图右上角有一个Last 7 days的显示,Query Options配置Relative time为7d即可
6.3 SQL
SELECT
now() time,
name,
COUNT(*) / COUNT(DISTINCT t_pipeline.server_name) weekly_prj_ci_cnt
FROM
t_pipeline,
repo,
t_component
WHERE
t_pipeline.server_name = repo.server_name
AND t_component.name=repo.component
AND t_component.name in ($ep_component)
AND repo.code_language in ($ep_code_language)
AND locate($ep_sp_project, repo.projects)
AND t_pipeline.created_at >= date_sub(now(), INTERVAL 7 day)
GROUP BY
name
ORDER BY weekly_prj_ci_cnt desc
- Format as选择Time series
- 在5.1的基础上,加上了GROUP BY,以及INTERVAL 7 day的汇总
二、数据下钻之原子操作
数据下钻,也就是通过某个特征或者条件进行更细层次的数据细分的呈现。
- 超链接
- 纯文本形式超链接
- SQL里面拼接链接
- Data Link
- 变量的使用
- Grafana data link
- Grafana links
1. 纯文本超链接
2.1 效果
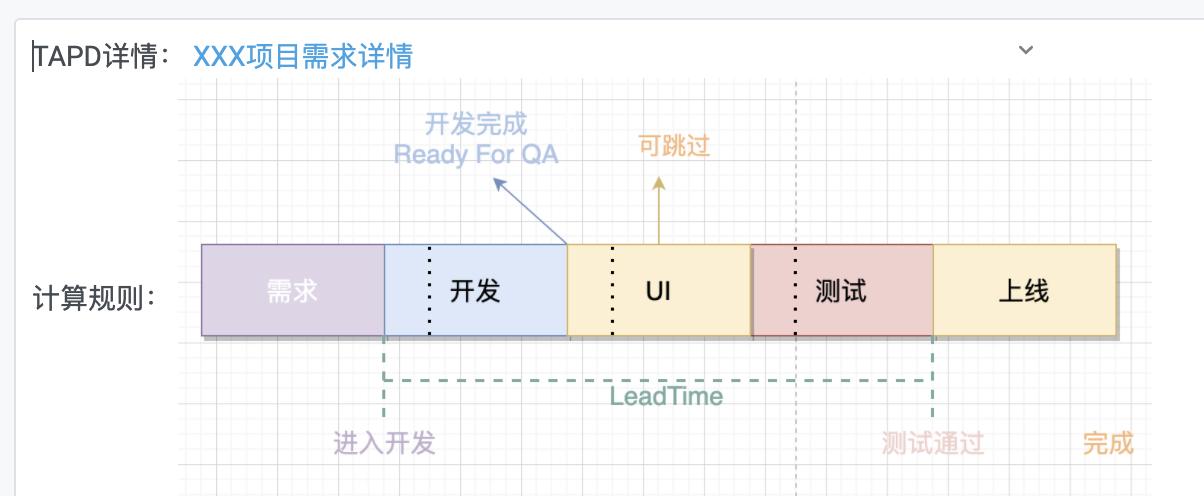
2.2 配置
-
Visualization:选择Text
-
Display:可选择HTML
TAPD详情:
<a href="http://xxx.oa.com/xxx/prong/stories/stories_list">XXX项目需求详情</a></td>
</br>
计算规则:
<img src="https://xxx.woa.com/files/photos/pictures/202105/1620358003_47_w1278_h584.png" width="50%"/>
2. SQL拼接链接
下面的示例SQL较为复杂,读者可根据自己选择的基本图形,合理运用CONCAT即可。
2.1 效果
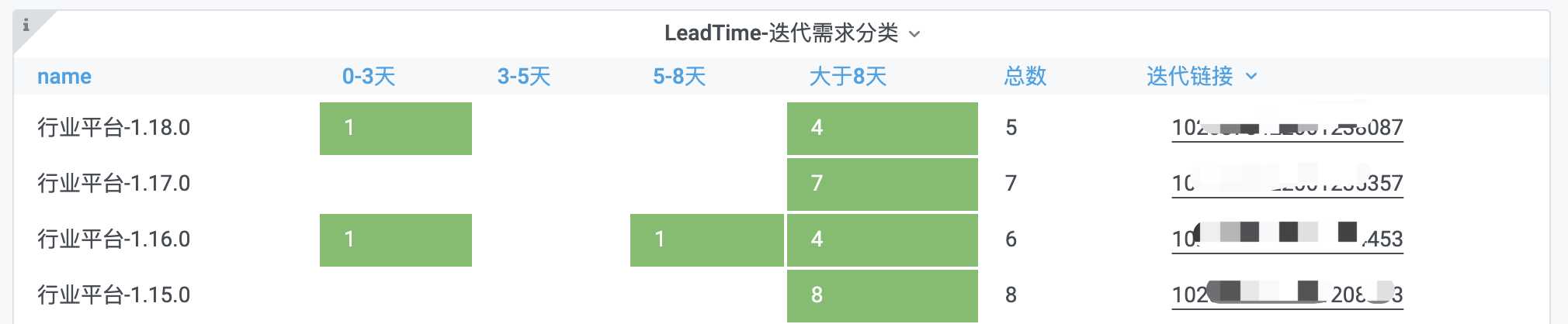
2.2 配置
-
Visualization:选择Table
-
Options
-
Data:Table Transform选择Table
-
Column Styles:Options中选择合适的列,开启Render value as link
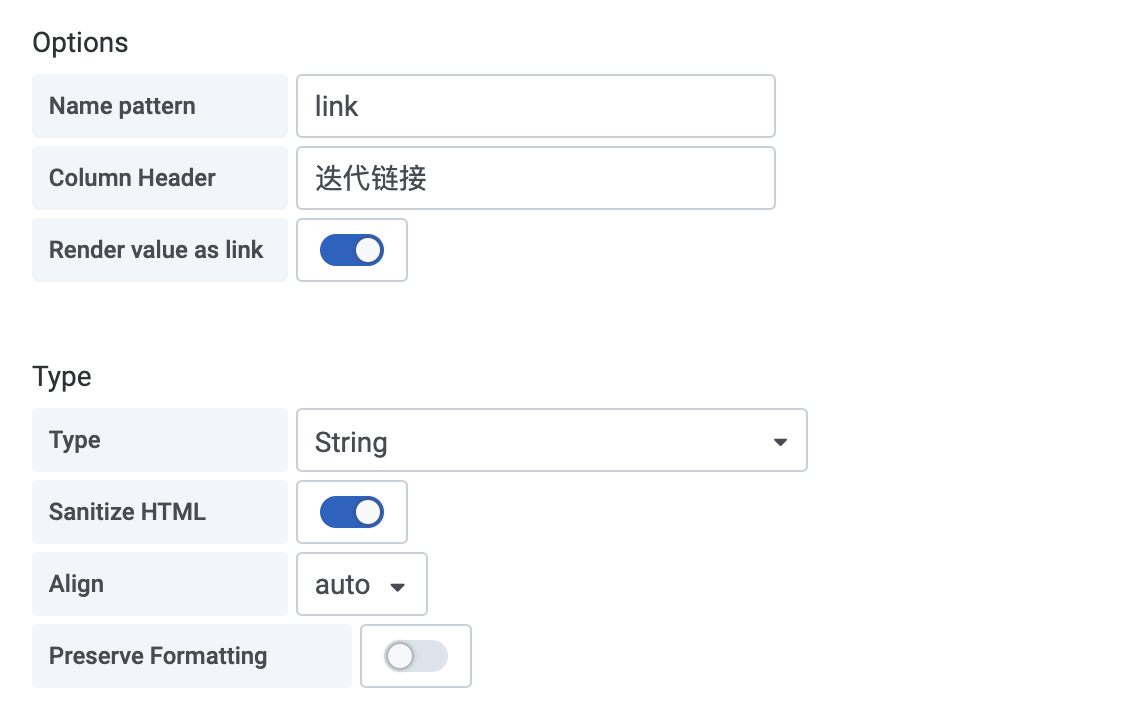
-
Thresholds中可选择Threadholds值,标注颜色,即可使上述表格cell为绿色。
-
2.3 SQL
SELECT
name,
SUM(zero) AS '0-3天',
SUM(three) AS '3-5天',
SUM(five) AS '5-8天',
SUM(eight) AS '大于8天',
SUM(total) AS '总数',
CONCAT(
"<a href='http://xxx.oa.com/",
tapd_workspace_id,
"/prong/iterations/view/",
tapd_iteration_id,
"' target='_blank'>",
tapd_iteration_id,
"</a>"
) AS `link`
FROM
(
SELECT
m.tapd_iteration_id,
m.tapd_workspace_id,
m.name,
(CASE WHEN m.days <= 3 THEN 1 ELSE 0 END) AS zero,
(CASE WHEN m.days > 3 AND m.days <= 5 THEN 1 ELSE 0 END) AS three,
(CASE WHEN m.days > 5 AND m.days <= 8 THEN 1 ELSE 0 END) AS five,
(CASE WHEN m.days > 8 THEN 1 ELSE 0 END) AS eight,
(CASE WHEN m.id <> '' THEN 1 ELSE 0 END) AS total
FROM
(
SELECT
i.name,
i.tapd_iteration_id,
i.tapd_workspace_id,
TIMESTAMPDIFF(MINUTE, for_dev_at, completed_at) / 1440 AS days,
s.id
FROM
t_tapd_story_stage s
LEFT JOIN t_tapd_iteration i ON s.iteration_id = i.tapd_iteration_id
WHERE
completed_at <> ''
AND $__timeFilter(i.enddate)
)m
)n
WHERE
total > 0
GROUP BY
tapd_iteration_id
ORDER BY
tapd_iteration_id ASC
3、变量
在dashboard的设置中定义的变量,可以作为该dashboard的全局变量使用。
3.1 回顾示例
示例可参考上述单一状态图,SQL如下:
SELECT
COUNT(DISTINCT t_pipeline.server_name) qci_prj_cnt
FROM
t_pipeline,
repo,
t_component
WHERE
t_pipeline.server_name = repo.server_name
AND t_component.name=repo.component
AND t_component.name in ($ep_component)
AND repo.code_language in ($ep_code_language)
AND locate($ep_sp_project, repo.projects)
- 出现了三个变量ep_component、ep_code_language、ep_sp_project
- 变量取值是从头部的导航栏的模块、语言、代码项目的下拉框处获得
3.2 配置
三个变量如下:
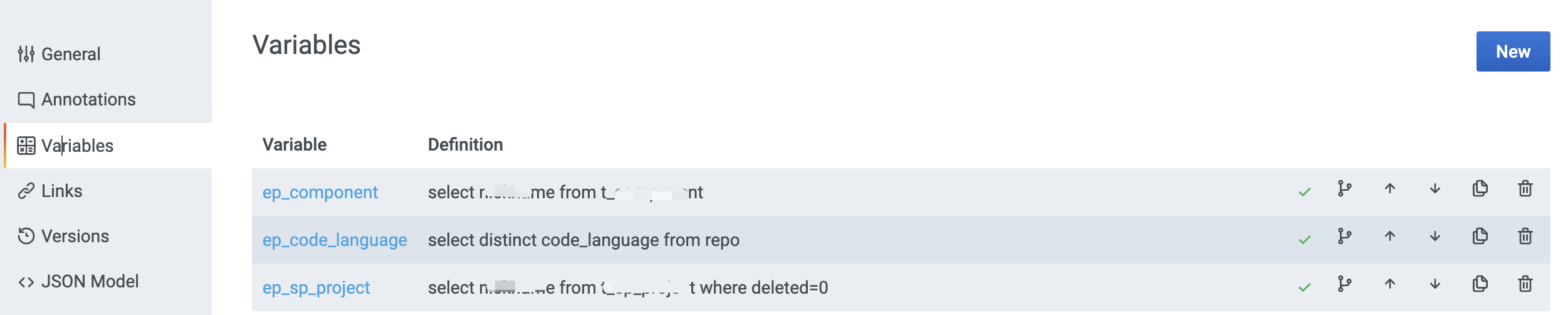
其中,ep_code_language详情如下: 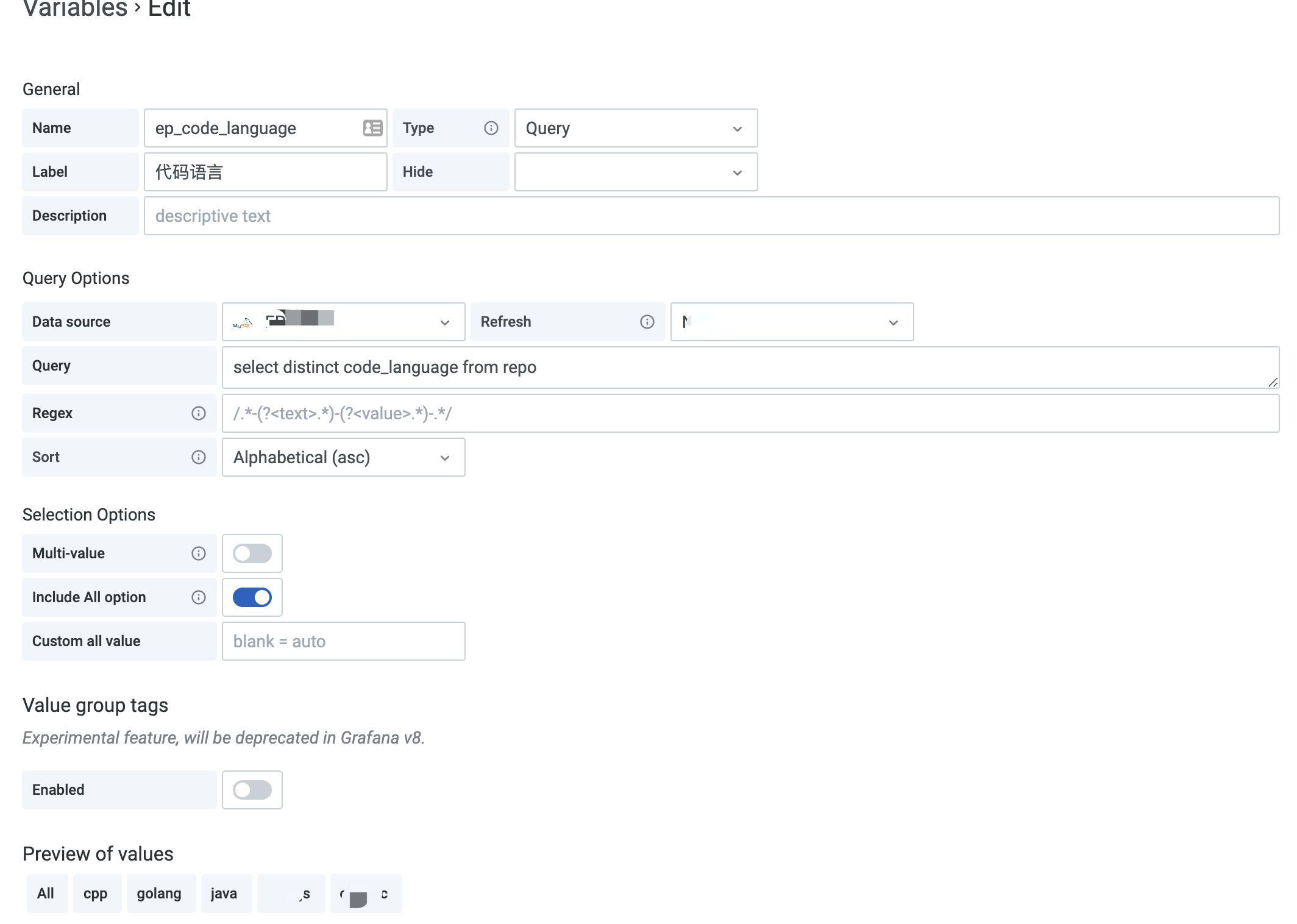
- 配置上述之后,即可以看到导航栏的下拉框了。当选择下拉框时,值就会通过$ep_code_language传入到SQL中。
- 注意在URL里面,Grafana会自动给变量加上前缀
var-,例如var-ep_code_language
4、Links
4.1 效果
左上角点击,即可展示链接标题:
4.2 配置
5、Data links
与Links的区别在于:
- Links跳转是在Panel的左上角,而Data links是在图表内容上进行点击跳转。
- Links基本上各个图形都有,而Data Links只有柱状图、折线图、表格才有。
5.1 效果
下面以表格为例,分为内部Grafana链接和外部TAPD的链接。(折线图和柱状图的示例详见实战部分)
- 点击每行的第一列,可跳转到Grafana另外一个图表。
- 点击每行的第二列,可跳转到TAPD的需求详情。
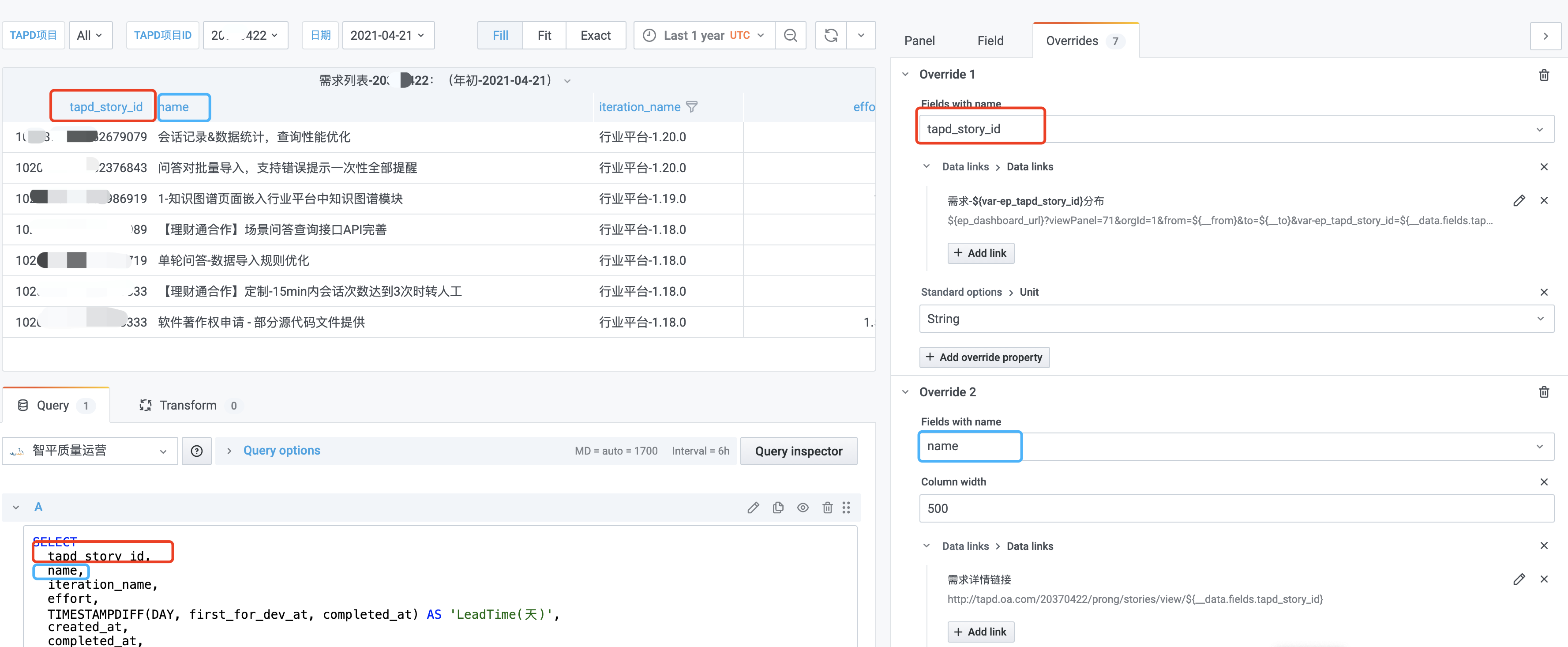
5.2 结合变量配置
在Data Link处,点击Add Link按钮,敲出$符号的时候,会自动弹出可选择的变量:
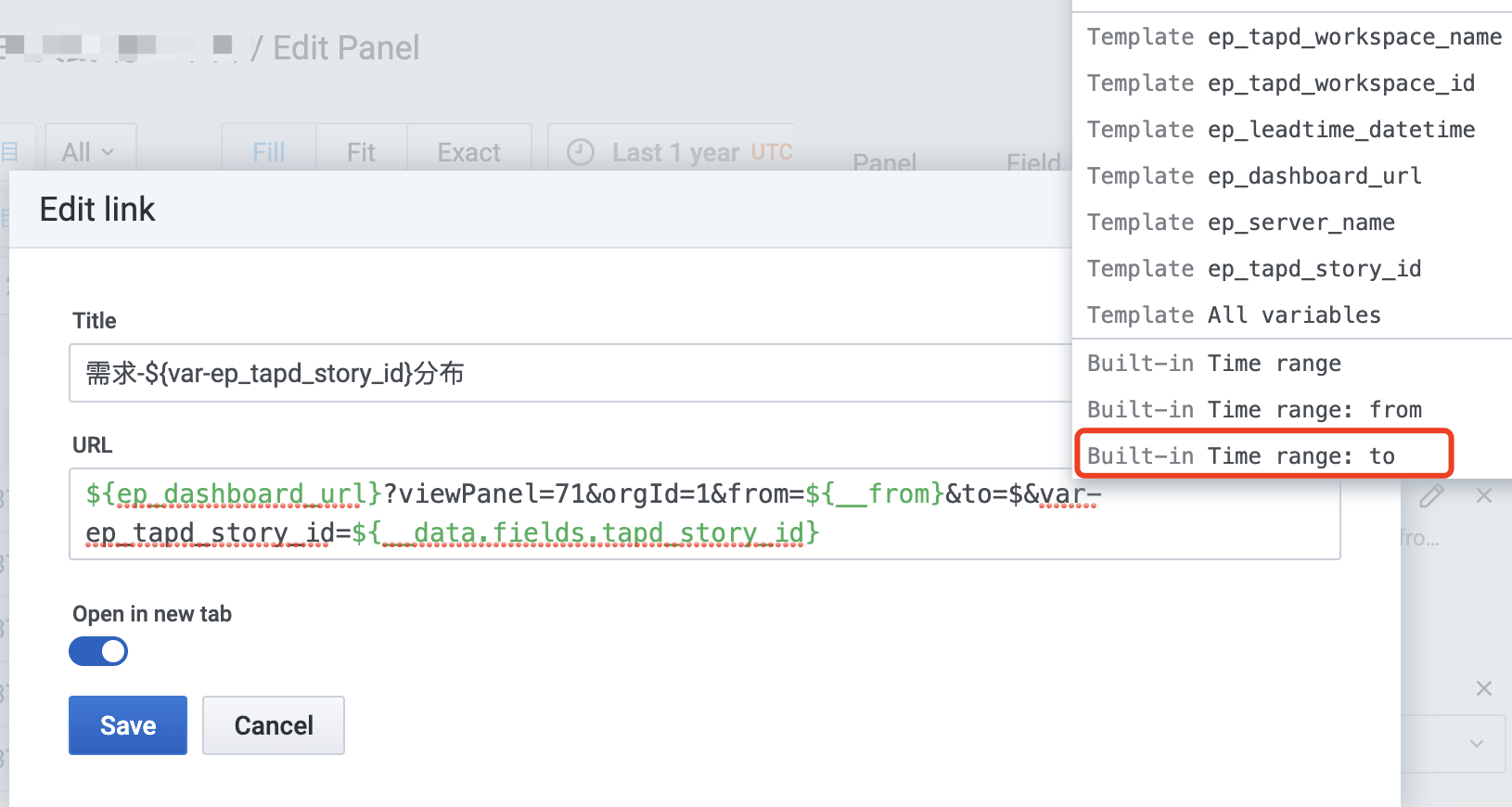
下图是针对内部Grafana的data link,和效果图中红色部分对应:
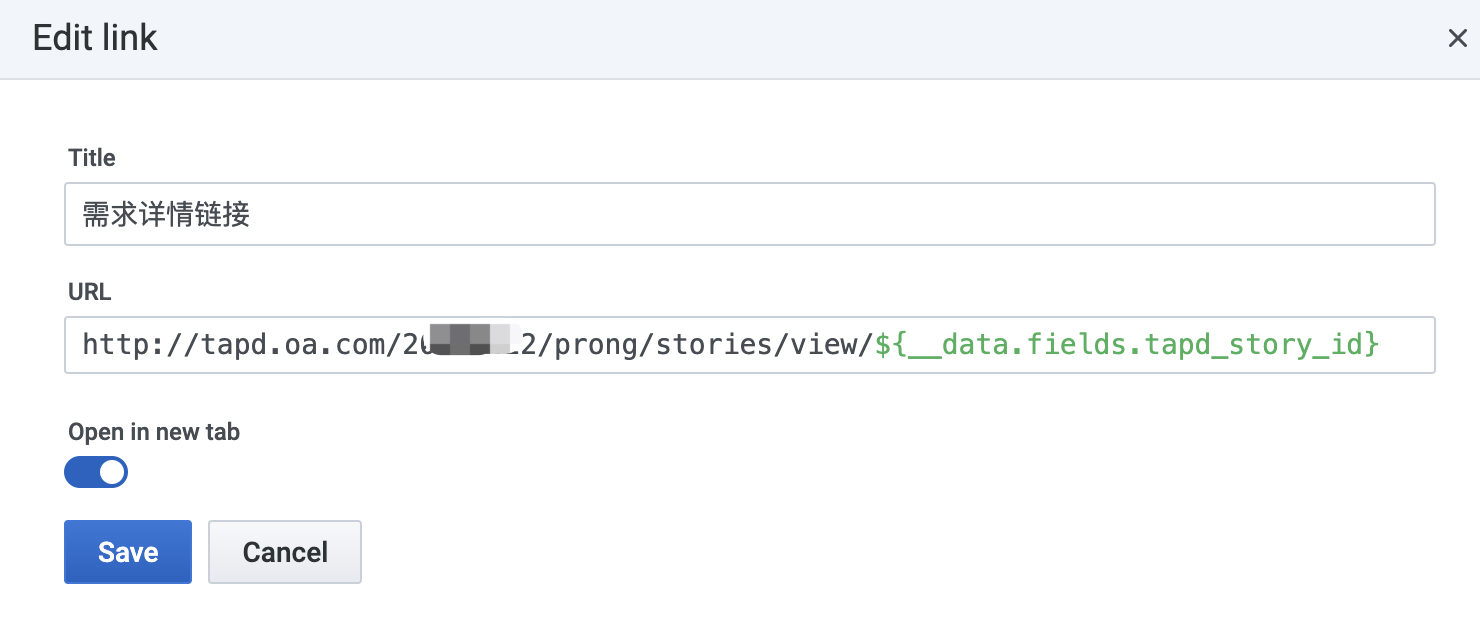
下图是针对外部TAPD的data link,和效果图中蓝色部分对应:
ep_dashboard_url,是一个Constant类型的变量__from和__to是系统变量__data.fields.tapd_story_id,是SQL select出来的结果ep_leadtime_datetime等,是自定义变量,通过URL传递到当前的data link中
三、LeadTime下钻实战
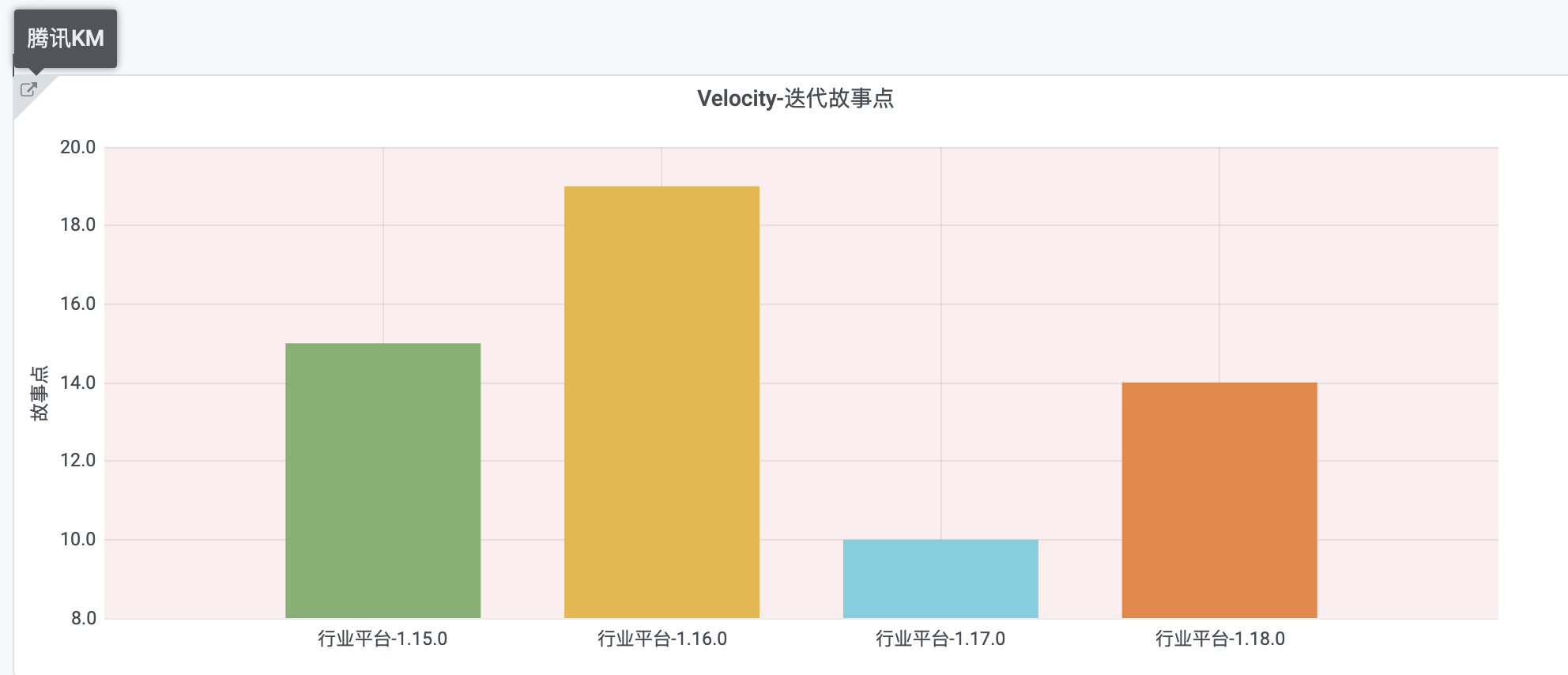
1、效果
1.1 总览
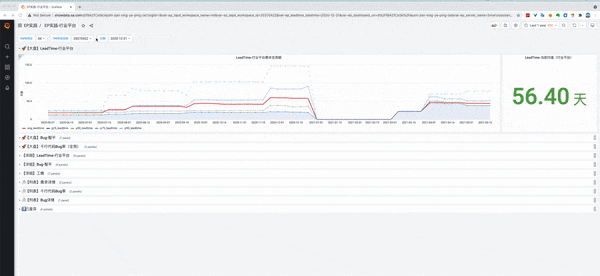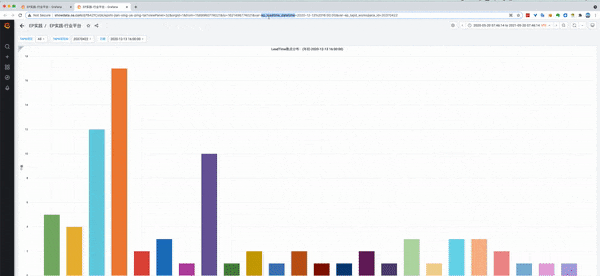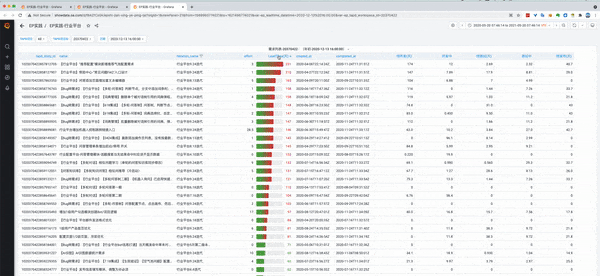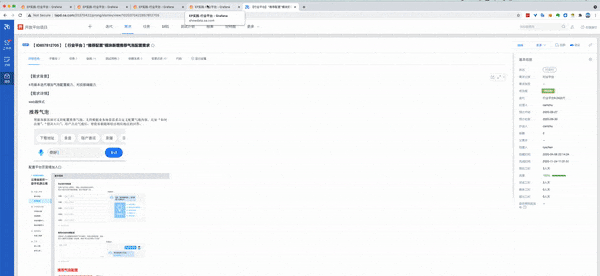
1.2 【一层】LeadTime大盘
大盘为第1层,是总体入口,点击折线图上某点,可以展示5个data links,进行第一次下钻到第2层。
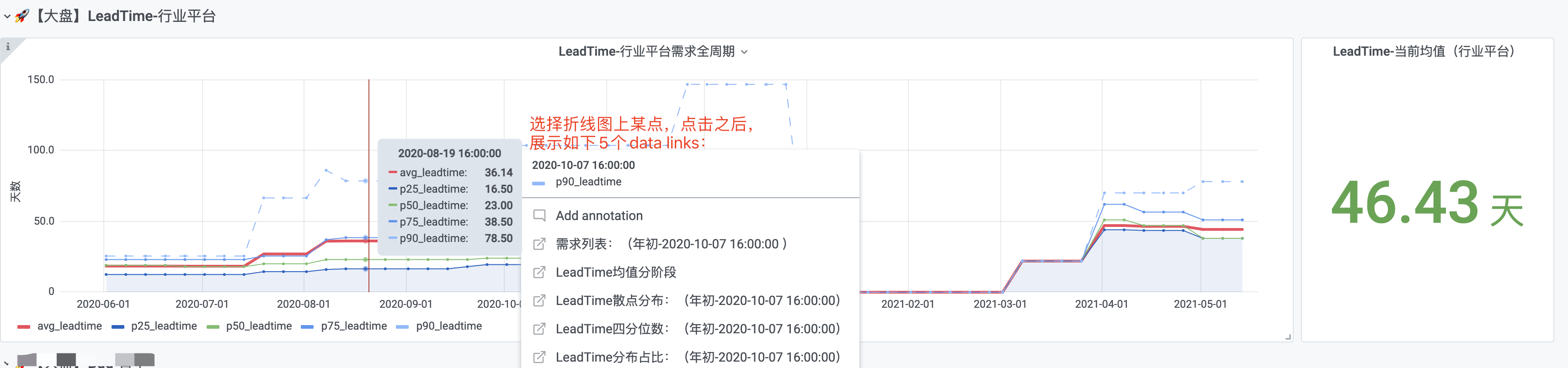
-
左图,采用折线图,展示了当前时间所在的年份里,所有需求花费时间的情况,包括均值、p25/p50/p75等
-
右图,采用单一状态图,单独将当前均值展示出来,比较醒目。
1.3 【二层】LeadTime散点分布
下图为第2层,是第一层选择LeadTime散点分布之后跳转得来,左上角可点击需求列表进入第3层。
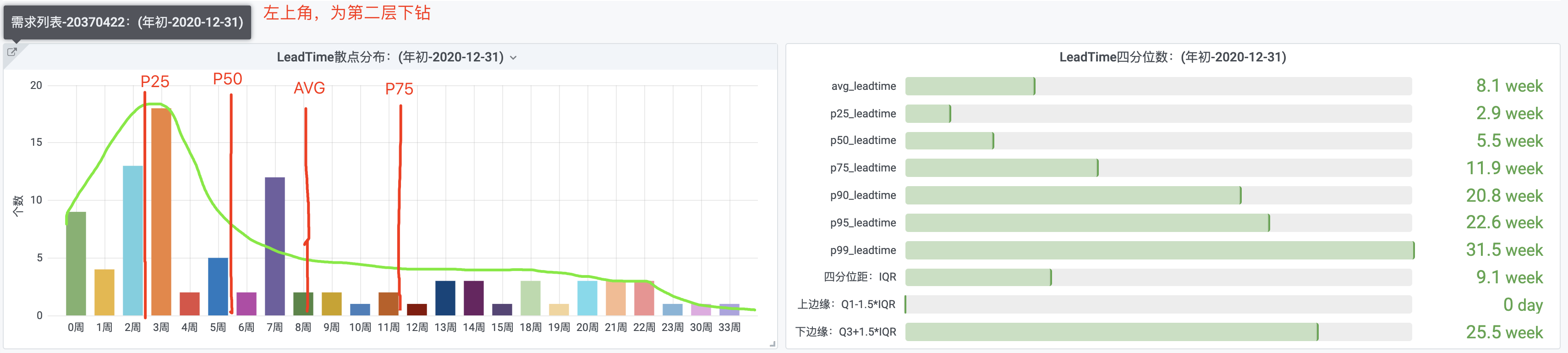
- 左图,采用柱状图,展示了当前年份里各个需求花费时间所对应的需求个数。
- 右图,采用Bar Guage的仪表盘,展示了当前年份里的四分位值,一定程度模拟了箱线图的数字。
- 将散点分布的柱状图用绿色的线连接起来,结合右边的avg_leadtime、p25/p50/p75,在作图上画出红色竖线,可以知道左图是一个右长尾。
1.4 【二层】LeadTime均值分阶段
下图为第2层,是第一次选择LeadTime均值分阶段之后跳转得来
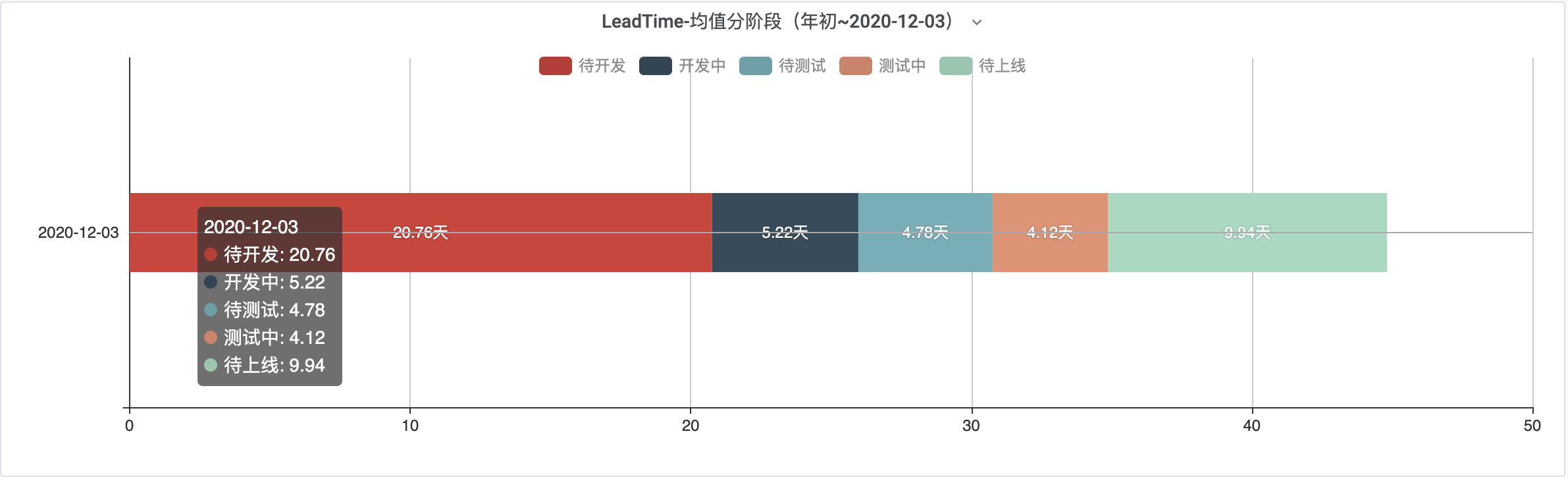
- 本图需要安装插件Echarts,选择Echarts插件。
- 本图展示选择时间点所在年初~选择时间点内需求,对齐进行各个阶段取均值
1.5 【三层】需求列表
下图为第3层,同时也可以由第1层直接跳转过来。
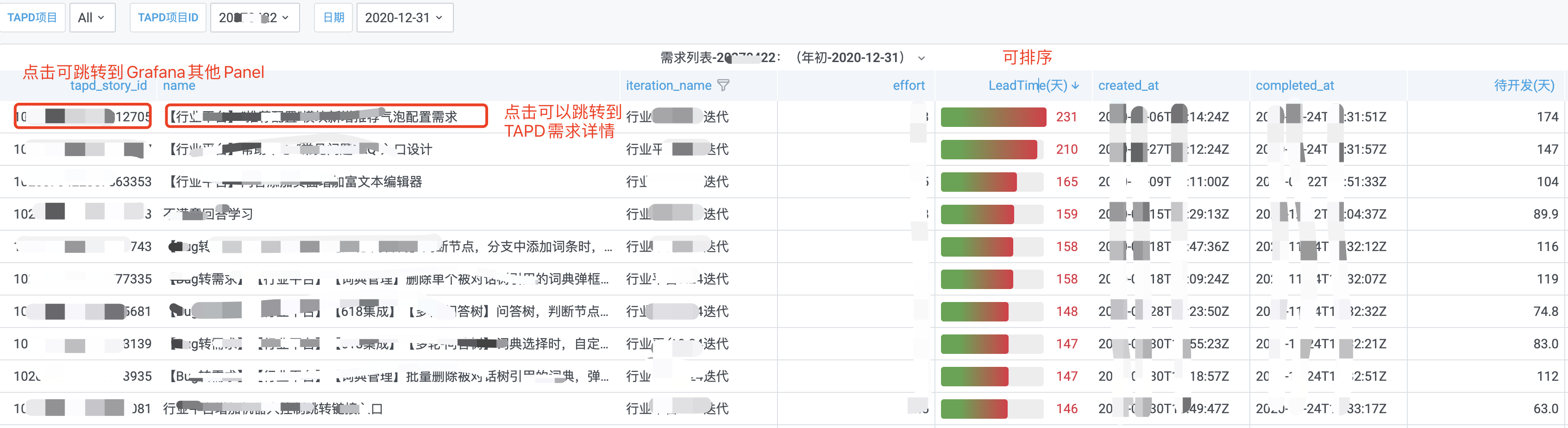
- 本图采用表格,结合数据下钻中的datalink部分,分别链接到了内部的Grafana链接和外部的TAPD链接。
- 点击左边第一列,可以跳转到Grafana其他Panel,展示需求时间分布比例
-
点击左边第二列,可以跳转到TAPD上需求的详情页面
- LeadTime可以排序,找到异常数据,进行分析。
1.6 【四层】需求时间分布比例
下图为第4层,由需求列表中点击第一行第一列数据跳转而来。

- 本图采用饼图,展示了该需求中各个阶段占用时间比例情况。
- 可以继续下钻,使用links,在左上角连接到该需求详情(此处没有实现)。
2、前提知识
上述Leadtime的数据采用了DA里面的箱线图,下面简单扫盲一下相关的概念:
2.1 箱线图
箱线图也称箱须图、箱形图、盒图,用于反映一组或多组连续型定量数据分布的中心位置和散布范围。 箱形图包含数学统计量,不仅能够分析不同类别数据各层次水平差异,还能揭示数据间离散程度、异常值、分布差异等等。
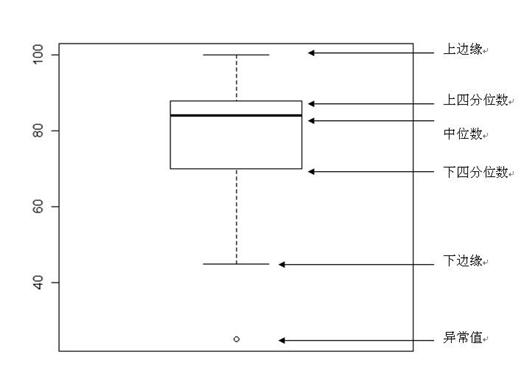
2.2 四分位数
一组数据按照从小到大顺序排列后,把该组数据四等分的数,称为四分位数。
- 上四分位数 (Q1),该样本中所有数值由小到大排列后第25%
- 中位数 (Q2),该样本中所有数值由小到大排列后第50%
- 下四分位数 (Q3),该样本中所有数值由小到大排列后第75%。
- 四分位距(IQR):第三四分位数与第一四分位数的差距IQR = Q3 - Q1。
- 上边缘:最大值,等于Q3 + 1.5 * IQR
- 下边缘:最大值,等于Q3 - 1.5 * IQR
2.3 偏态
与正态分布相对,指的是非对称分布的偏斜状态。
在统计学上,众数和平均数之差可作为分配偏态的指标之一:如平均数大于众数,称为正偏态(或右偏态);相反,则称为负偏态(或左偏态)。
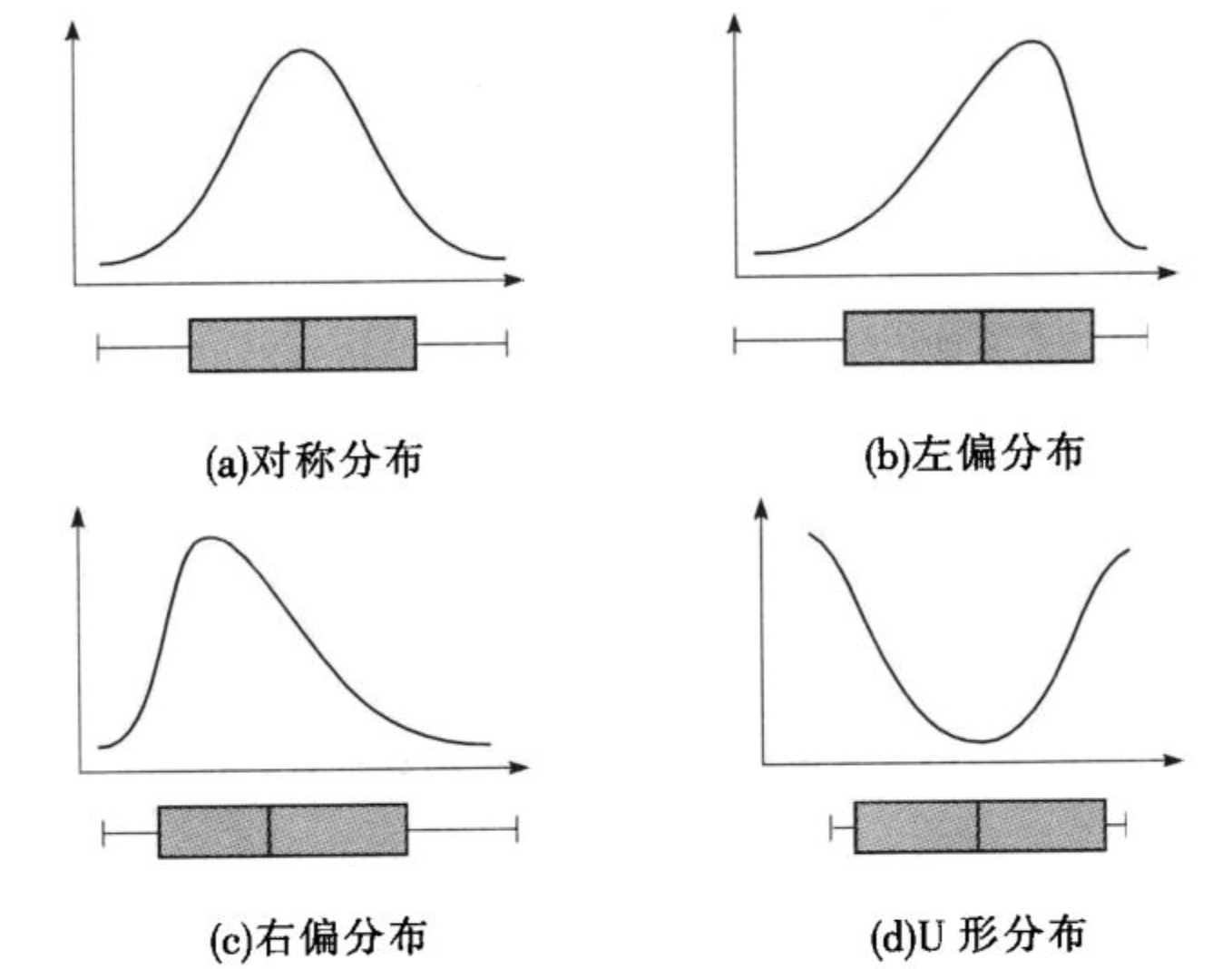
3、实现
基本图形已经在本文的第一部分呈现了,下面只放一些重点部分。具体步骤分为:
-
创建变量
-
创建各层图表
-
使用Data link将各层图表连接起来
3.1 变量
涉及到的变量如下:
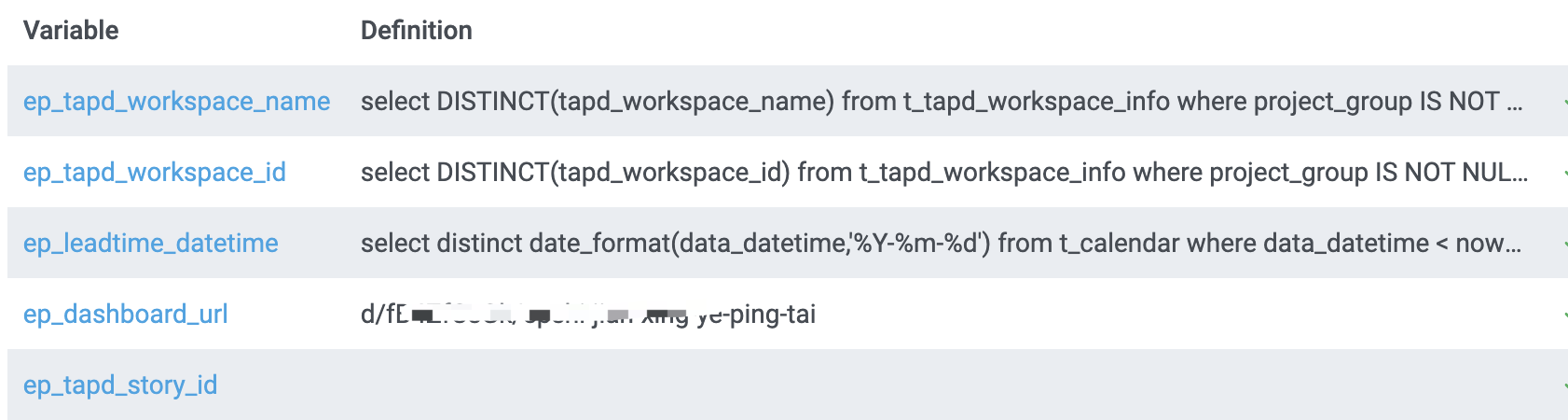
-
前面三个都是Query类型
-
ep_dashboard_url是Constant类型
-
ep_tapd_story_id是Text Box类型,Hide选择Variable,只是用于URL参数传递,不用在导航栏的下拉框选择。
-
注意,当你手动在浏览器更改URL的时候,变量需要加上前缀
var-,比如ep_tapd_workspace_id
3.2 【一层】LeadTime大盘
Query SQL如下:
SELECT
unix_timestamp(date_add(c.data_datetime, interval 1 day)) as time,
avg_leadtime,
p25_leadtime,
p50_leadtime,
p75_leadtime,
p90_leadtime
from
t_calendar c
JOIN t_leadtime_distribution_percentile p ON c.data_datetime = p.data_datetime
WHERE
$__timeFilter(c.data_datetime)
AND DAYOFMONTH(c.data_datetime) in (1, 7, 13, 19, 25)
链接到【3.3】第2层的Data links如下:
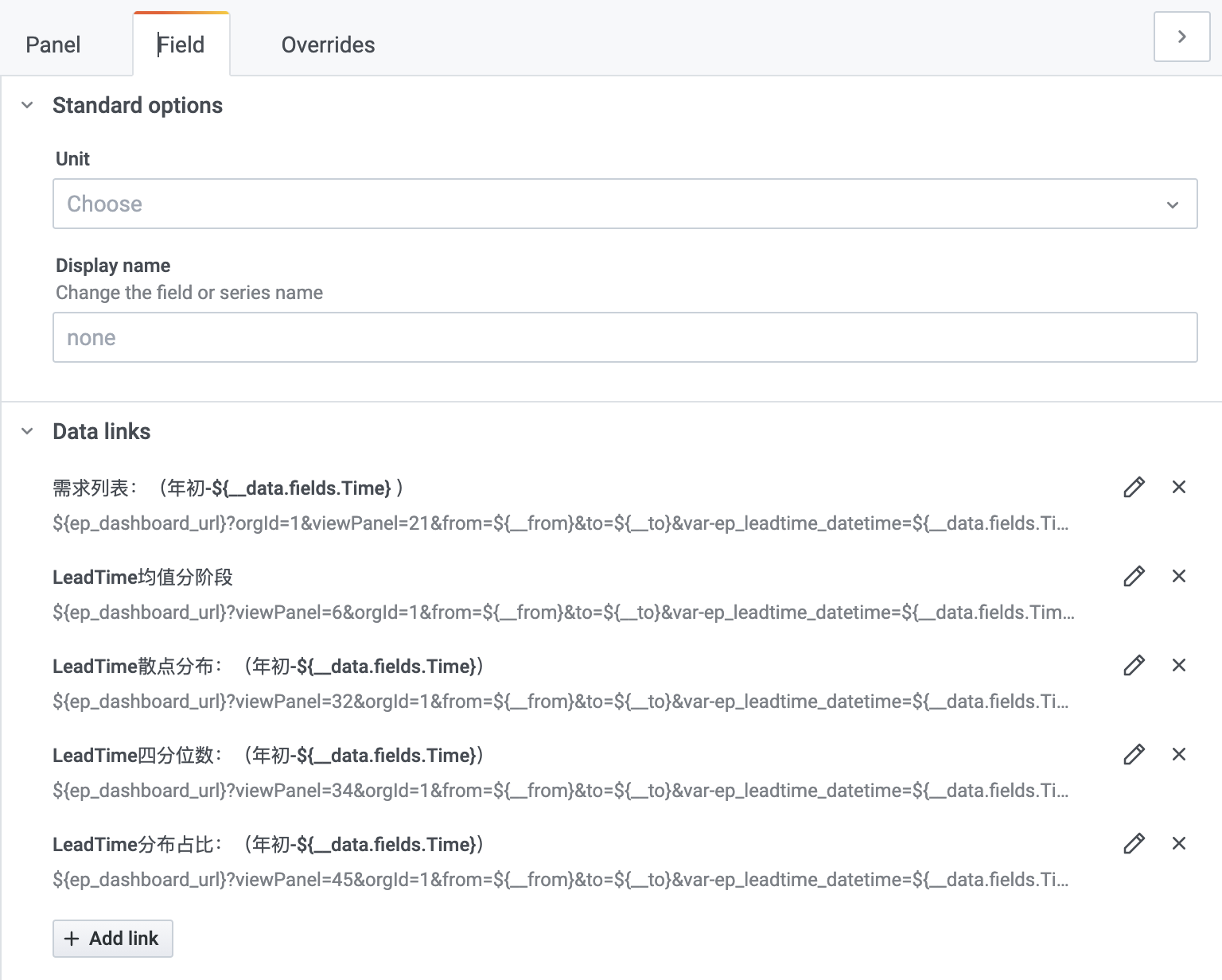
其中散点分布的Data links内容如下,viewPanel=32,32是二层Panel的ID:
- 标题:
LeadTime散点分布:(年初-${__data.fields.Time}) - URL:
${ep_dashboard_url}?viewPanel=32&orgId=1&from=${__from}&to=${__to}
&var-ep_leadtime_datetime=${__data.fields.Time}
&var-ep_tapd_workspace_id=${ep_tapd_workspace_id}
3.3 【二层】LeadTime散点分布
Query SQL如下:
SELECT
now() time,
CONCAT(TIMESTAMPDIFF(WEEK, first_for_dev_at, completed_at), '周') AS leadtime,
count(tapd_story_id) AS '数量'
FROM
t_tapd_story_stage
WHERE
tapd_workspace_id = '$ep_tapd_workspace_id'
AND created_at > date_format('$ep_leadtime_datetime', '%Y-01-01')
AND (completed_at BETWEEN date_format('$ep_leadtime_datetime', '%Y-01-01') AND '$ep_leadtime_datetime')
GROUP BY TIMESTAMPDIFF(WEEK, first_for_dev_at, completed_at)
链接到【3.5】第3层需求列表的左上角Links如下:
- 标题:
需求列表-${ep_tapd_workspace_id}:(年初-$ep_leadtime_datetime) - URL:
${ep_dashboard_url}?orgId=1&viewPanel=21&from=${__from}&to=${__to}
&var-ep_leadtime_datetime=${ep_leadtime_datetime}
&var-ep_tapd_workspace_id=${ep_tapd_workspace_id}
3.4 【二层】LeadTime均值分阶段
Query SQL:
SELECT
date_format(data_datetime, '%Y-%m-%d') as 'category',
(
SELECT
AVG(waiting_before_dev)
FROM
t_tapd_story_stage s
WHERE
s.tapd_workspace_id = "${ep_tapd_workspace_id}"
AND s.created_at >= date_format(data_datetime, '%Y-01-01')
AND waiting_before_dev >= 0
AND (s.completed_at BETWEEN date_format(data_datetime, '%Y-01-01') AND date_format(data_datetime, '%Y-%m-%d'))
) as '待开发',
(
SELECT
AVG(in_dev)
FROM
t_tapd_story_stage s
WHERE
s.tapd_workspace_id = "${ep_tapd_workspace_id}"
AND s.created_at >= date_format(data_datetime, '%Y-01-01')
AND in_dev >= 0
AND (s.completed_at BETWEEN date_format(data_datetime, '%Y-01-01') AND date_format(data_datetime, '%Y-%m-%d'))
) as '开发中',
(
SELECT
AVG(waiting_before_qa)
FROM
t_tapd_story_stage s
WHERE
s.tapd_workspace_id = "${ep_tapd_workspace_id}"
AND s.created_at >= date_format(data_datetime, '%Y-01-01')
AND waiting_before_qa >= 0
AND (s.completed_at BETWEEN date_format(data_datetime, '%Y-01-01') AND date_format(data_datetime, '%Y-%m-%d'))
) as '待测试',
(
SELECT
AVG(in_qa)
FROM
t_tapd_story_stage s
WHERE
s.tapd_workspace_id = "${ep_tapd_workspace_id}"
AND s.created_at >= date_format(data_datetime, '%Y-01-01')
AND in_qa >= 0
AND (s.completed_at BETWEEN date_format(data_datetime, '%Y-01-01') AND date_format(data_datetime, '%Y-%m-%d'))
) as '测试中',
(
SELECT
AVG(waiting_before_release)
FROM
t_tapd_story_stage s
WHERE
s.tapd_workspace_id = "${ep_tapd_workspace_id}"
AND s.created_at >= date_format(data_datetime, '%Y-01-01')
AND waiting_before_release >= 0
AND (s.completed_at BETWEEN date_format(data_datetime, '%Y-01-01') AND date_format(data_datetime, '%Y-%m-%d'))
) as '待上线'
from
t_calendar
where data_datetime = '${ep_leadtime_datetime}'
- 标题:LeadTime-均值分阶段(年初~${ep_leadtime_datetime})
- Format as选择Table
- Echarts Options:
const axisOption = {
axisTick: {
show: false,
},
axisLine: {
show: true,
},
axisLabel: {
color: 'rgba(128, 128, 128, .9)',
},
splitLine: {
lineStyle: {
color: 'rgba(128, 128, 128, .2)',
},
},
};
const data_serise = function(){
data_from_sql = data.series[0].fields
xData = []
seData = []
leData = []
data_from_sql.forEach(function (item, index, array) {
if (item.name == "category"){
xData.push(item.values.buffer[0])
}
if (item.type == "number"){
show_data = item.values.buffer
result = []
show_data.forEach(function (item, idnex, array) {
result.push(item.toFixed(2)) ;
});
seData.push({
name: item.name,
barWidth: 60,
type: 'bar',
stack: 1,
label: {show: true, formatter: '{c}天'},
data: result,
});
leData.push(item.name)
}
});
return {'xData': xData, 'se':seData, 'leData': leData};
}
options = {
backgroundColor: 'transparent',
tooltip: {
trigger: 'axis',
},
legend: {
data: data_serise().leData,
textStyle: {
color: 'rgba(128, 128, 128, .9)',
},
},
yAxis: [
{
type: 'category',
data: data_serise().xData
}
],
xAxis: [
{
type: 'value',
max : 50
}
],
grid: {
left: 20,
right: 16,
top: 6,
bottom: 24,
containLabel: true,
},
series: data_serise().se,
};
return options;
3.5 【三层】需求列表
Query SQL:
SELECT
tapd_story_id,
name,
iteration_name,
effort,
TIMESTAMPDIFF(DAY, first_for_dev_at, completed_at) AS 'LeadTime(天)',
created_at,
completed_at,
CONVERT(waiting_before_dev, DECIMAL (10, 2)) AS '待开发(天)',
in_dev AS '开发中',
CONVERT(waiting_before_qa, DECIMAL (10, 2)) AS '待测试(天)',
in_qa AS '测试中',
CONVERT(waiting_before_release, DECIMAL (10, 2)) AS '待发布(天)'
FROM t_tapd_story_stage
WHERE
tapd_workspace_id = "$ep_tapd_workspace_id"
AND created_at > date_format('$ep_leadtime_datetime', '%Y-01-01')
AND (completed_at BETWEEN date_format('$ep_leadtime_datetime', '%Y-01-01') AND '$ep_leadtime_datetime')
ORDER BY iteration_name DESC
链接到【3.6】第四层需求时间分布比例的Data Links如下:
- 标题:
需求-${ep_tapd_story_id}分布 - URL:
${ep_dashboard_url}?viewPanel=71&orgId=1&from=${__from}
&to=${__to}&var-ep_tapd_story_id=${__data.fields.tapd_story_id}
3.6 【四层】需求时间分布比例
第四层直接从URL中通过"${ep_tapd_story_id}"获取条件,进行查询,展示饼图。
四、结语
1、小结
对于一个稳定的业务形态,有时候有些复杂的可视化需求,开发一个平台,前端实现页面跳转,可以沉淀系统化能力,也方便扩展。
但是,对于需要Spike图表展示方式,且需要灵活的数据分析的时候,用Grafana结合数据库,提供一个全局的面板,不失为一个快速响应的方式。
图表多了,就会混乱,即便是放在不同的dashboard、row里进行折叠管理,当打开多个图表的时候,也会眼花缭乱,网上关于datalinks的文章比较少,故以此记之。
2、相关阅读
- Grafana Zabbix Demo,可参考图对应的SQL