一、前言
《Docker in Production》 workshop于2017年9月23在ThoughtWorks武汉举办,之后,有懒癌的笔者就”忘记”去接着更新这一系列了。 直到上次上线(OTR Diaochan Release)出现了一些问题,在寻找问题过程中,docker的日志、监控、Dashboard这一主题发挥了很重要的作用,才想起来该好好整理下这一篇文章。
二、背景
该系列《Docker in Production》内容包含如下部分:
- 容器简介
- Docker简介
- Docker的基本操作
- Docker数据存储
- Docker网络
- Docker安全
- 多主机部署
- 服务发现
- 日志、监控、Dashboard
三、日志
1. 传统日志处理
传统的日志处理,是将日志写到本机磁盘上,通常仅用于排查线上问题,很少用于数据分析。 等需要时,再登录到机器上,用grep、awk等工具分析。那么,这种方式有什么缺点呢?
-
1.它的效率非常低,因为每一次要排查问题的时候都要登到机器上去,当有几十台或者是上百台机器的时候,每一台机器去登陆这是一个没办法接受的事情,可能一台机器浪费两分钟,整个几小时就过去了。
-
2.如果要进行一些比较复杂的分析,像grep、awk两个简单的命令不能够满足需求时,就需要运行一些比较复杂的程序进行分析。
-
3.日志本身它的价值不光在于排查一些系统问题上面,可能在一些数据的分析上,可能利用日志来做一些用户的决策,这也是它的价值,如果不能把它利用起来,价值就不能充分的发挥出来。
2. docker日志处理
Docker daemon与Docker container的联系:
一个docker的container就是一个特殊的进程,它是由docker daemon创建并启动。 因此container是docker daemon的子进程,由docker daemon守护和管理。
与Docker相关的日志主要有两部分:
-
Docker Daemon日志,即Docker自身运行产生的日志。
-
Docker Container日志,即Docker容器应用产生的日志。容器日志的两种输出形式:
- stdout、stderr 标准输出
- 日志文件记录
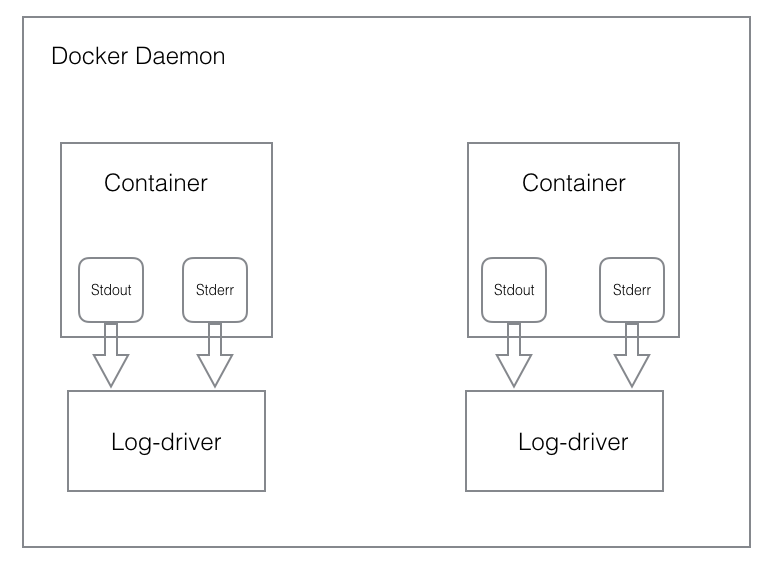
标准输出日志,其原理在于,当在启动进程的时候,进程之间有一个父子关系,父进程可以拿到子进程的标准输出。拿到子进程标准输出的后,父进程可以对标准输出做所有希望的处理。
日志文件记录,在Docker 1.6以前,Docker仅仅是从容器中采集stdout和stderr,然后用JSON进行简单的封装并存储到磁盘。Docker 1.6以后,引入了日志驱动(Log Drivers) 。 LogDriver就是Docker用来处理容器标准输出的一个模块,Docker支持很多种不同的处理方式,如下表所示:
| Driver | Description |
|---|---|
| none | 丢弃容器输出,docker logs命令也看不到任何内容 |
| json-file | 默认驱动,使用json文件保存日志 |
| syslog | 将日志写入syslog里,syslog必须在机器上启动 |
| journald | 将日志发送到journald(systemd),journald必须在机器上启动 |
| gelf | 将日志发送到GELF端点,如Graylog或Logstash |
| fluentd | 将日志发送给fluentd,fluentd必须在机器上启动 |
| awslogs | 将日志发送给Amazon Cloudwatch |
| splunk | 将日志发送到splunk |
| etwlogs | 将日志发送给Event Tracing for Windows。仅在windows平台可用 |
| gcplogs | 将日志发送给Google日志系统 |
| nats | 将日志发送给NATS服务 |
目前,只有json-file和journald可以通过docker logs和docker-compose logs显示日志,其他方式有其他日志查看方式。
3. 集中式日志聚合
当系统中的节点增加到多个节点,管理和访问日志会变得复杂。如果没有合适的工具,要从上百个节点上的上百个日志文件中搜索出错误日志会变得很困难。常见解决思路是建立集中式日志收集系统(Centralized Logging),将所有节点上的日志统一收集,管理,访问。
集中式日志聚合有两种思路:
- 在所有的容器里运行一个辅助进程,该进程充当agent并将日志发到我们的聚合service里。
- 在主机上或者是在一个单独的容器里,收集日志并转发到聚合service里。
第一种方式经常用到,但是它可能会让镜像变大,并且必要地增加了运行的进程数量:
- 1.因为每个容器都有一个日志的进程,意味着你的机器上面有100个容器,就需要启动一百个日志设备的程序,资源的浪费非常厉害。
- 2.在做镜像的时候,需要把容器里面日志采集程序做到镜像里面去,对你的镜像其实是有入侵的,为了日志采集,不得不把自己的日志程序再做个新镜像,然后把东西放进去,所以对你的镜像过程是有入侵性的。
- 3.当一个容器里面好多个进程的时候,对于容器的资源管理,会干扰你对容器的资源使用的判断,包括对于在做资源分配和监控的时候,都会有一些这样的干扰。
目前最流行的日志聚合解决方案是ELK(Logstash、Elasticsearch、Kibana): 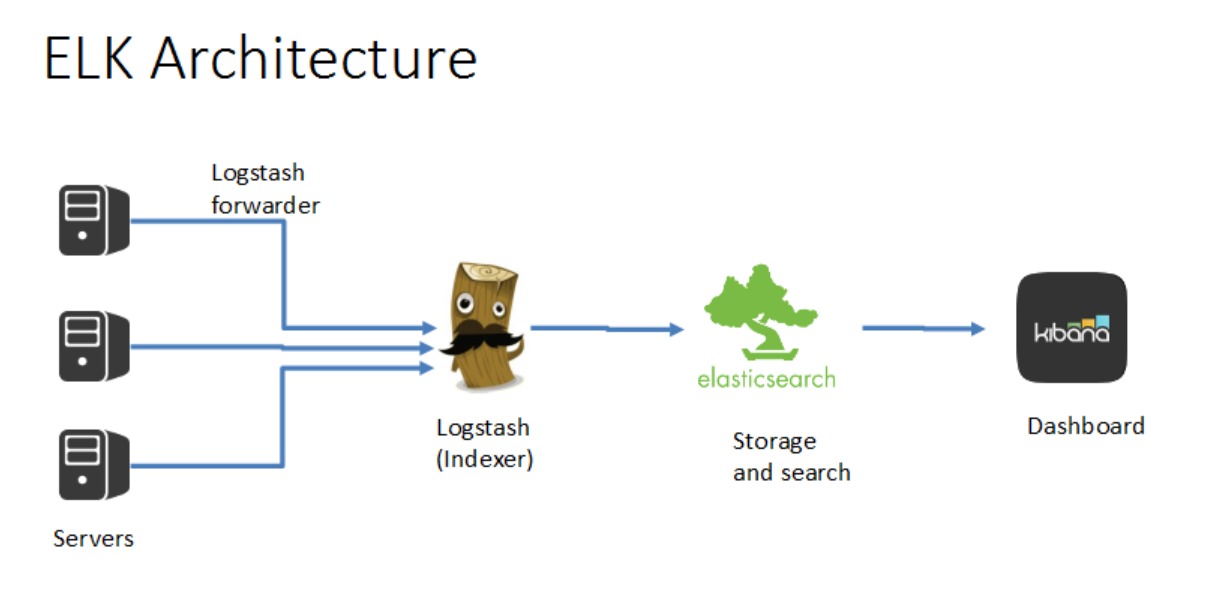
- Shipper - logstash forward是一个Shipper,用来放到各个主机中收集指定位置的日志,将收集到日志发送到 Logstash。
- Logstash - Logstash用来收集、过滤、转发日志。
- Elasticsearch - Elasticsearch是一个基于Lucene的、支持全文索引的分布式存储和索引引擎,主要负责将日志索引并存储起来,方便业务方检索查询。
- Kibana 是一个可视化工具,主要负责查询数据并以可视化的方式展现给业务方,比如各类饼图、直方图、区域图等。
4. Out of scope
那么,我们怎么样去收集日志、存储日志,用什么样的系统,日志的源头和写日志我们又该怎么来做,有这样几个建议:
- 选择合适的日志框架,不要直接print
- 为每一条日志选择正确的level,该debug的不要用info;
- 附加更多的上下文信息;
- 使用json、csv等日志格式,方便工具解析;
- 尽量不要使用多行日志(Java Exception Stack)。
四、监控
1. 为什么进行日志监控?
- 提前地,可以在用户致电报错之前,了解问题。
- 问题上,可以获得相关信息,并进行分析解决。
- 潜在地,可以在潜在问题造成影响之前,发现可疑活动。
- 技术上,可以建立一个周期性的性能基线,获取各项指标。
- 业务上,可以利用日志文件的数据进行战略和战术决策。
2. 监控对象与指标
- 硬件监控
- CPU温度
- 物理磁盘
- 虚拟磁盘
- 主板温度
- 磁盘阵列
- 系统监控
- CPU
- 磁盘(吞吐量、读写次数)
- 内存(使用量、剩余量)
- 网络
- 进程
- 应用监控
- 应用程序
- 数据库
- 网络监控
- 响应时间
- 可用率
- 流量分析
- 访客分析
- 来源分析
- 页面分析
- 日志监控
- 访问日志
- 错误日志
- 运行日志
- 网络日志
- 安全监控
- SQL注入
- 跨站脚本
- 代码执行漏洞
- 扫码探测
- API监控
- 可用性
- 正确性
- 响应性
- 性能监控
- DNS响应时间
- HTTP建立连接时间
- 页面性能指数
- 响应时间
- 可用率
- 业务监控
- 每分钟产生多少订单
- 每分钟注册多少用户
- 每天有多少活跃用户
- 每天有多少推广活动
- 推广活动引入多少用户
- 推广活动引入多少流量
3. 监控流程
- 数据采集
- 数据存储
- 数据分析
- 数据展示
- 监控报警
- 报警处理
五、Dashboard
1. 为什么要仪表盘?
- 数据可视化(度量信息,关键业务指标)
- 交互式界面(从多个数据源获取数据,并定制化交互式界面)
- 提升用户体验(清晰地传达关键信息给用户,信息能够快速被理解)
2. 可视化哪些信息?
- 应用的健康状况
- 错误统计和走势
- 资源利用率和走势
- 全部生产力
- 部署次数,版本,响应时间, 等等.
- 业务指标
最后
关于日志、监控、可视化,虽然有很多工具可以帮我们实现,比如监控上的Prometheus、AppDynamic,比如ELK的一整套解决方案,但是了解背后的本质与为什么是尤为重要的。